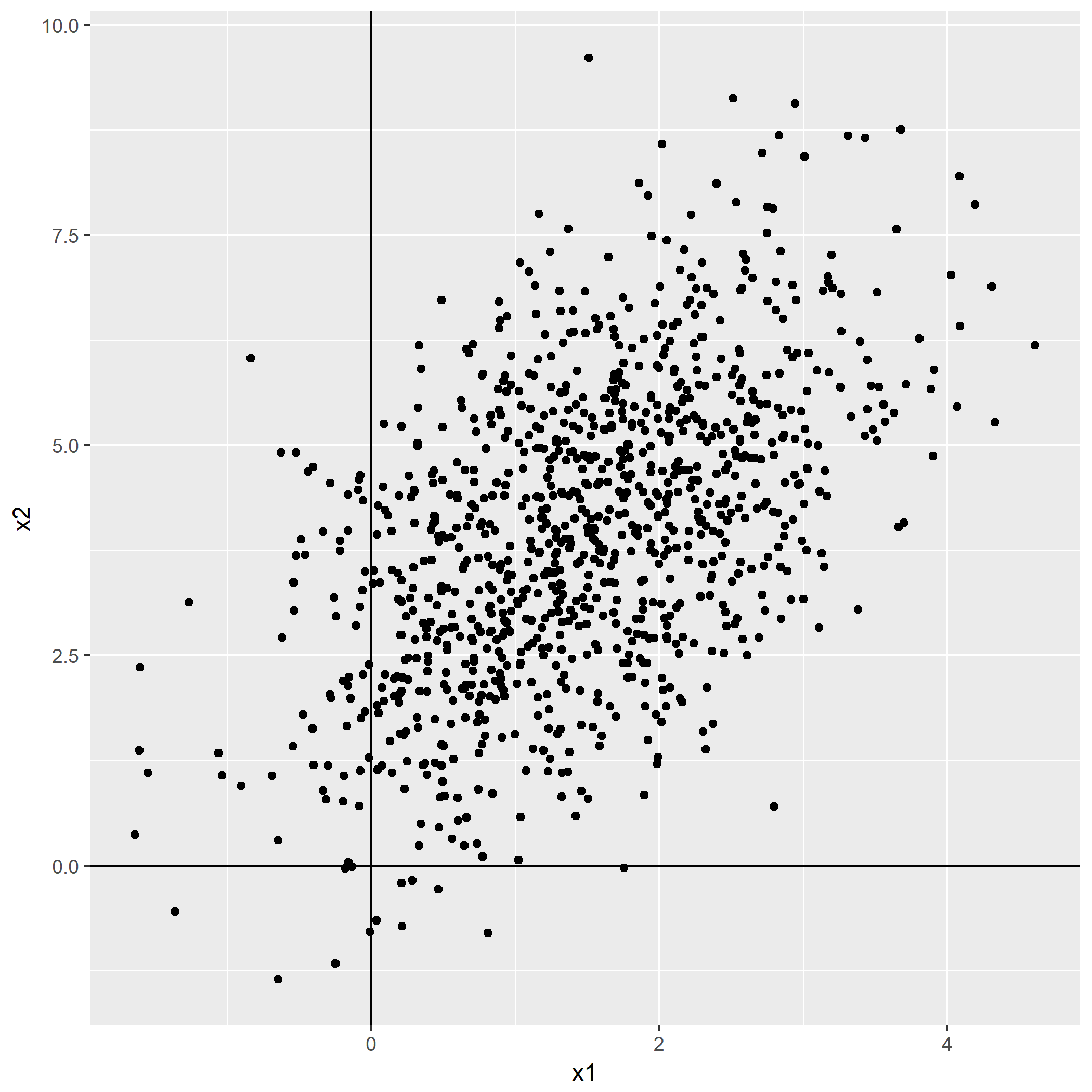
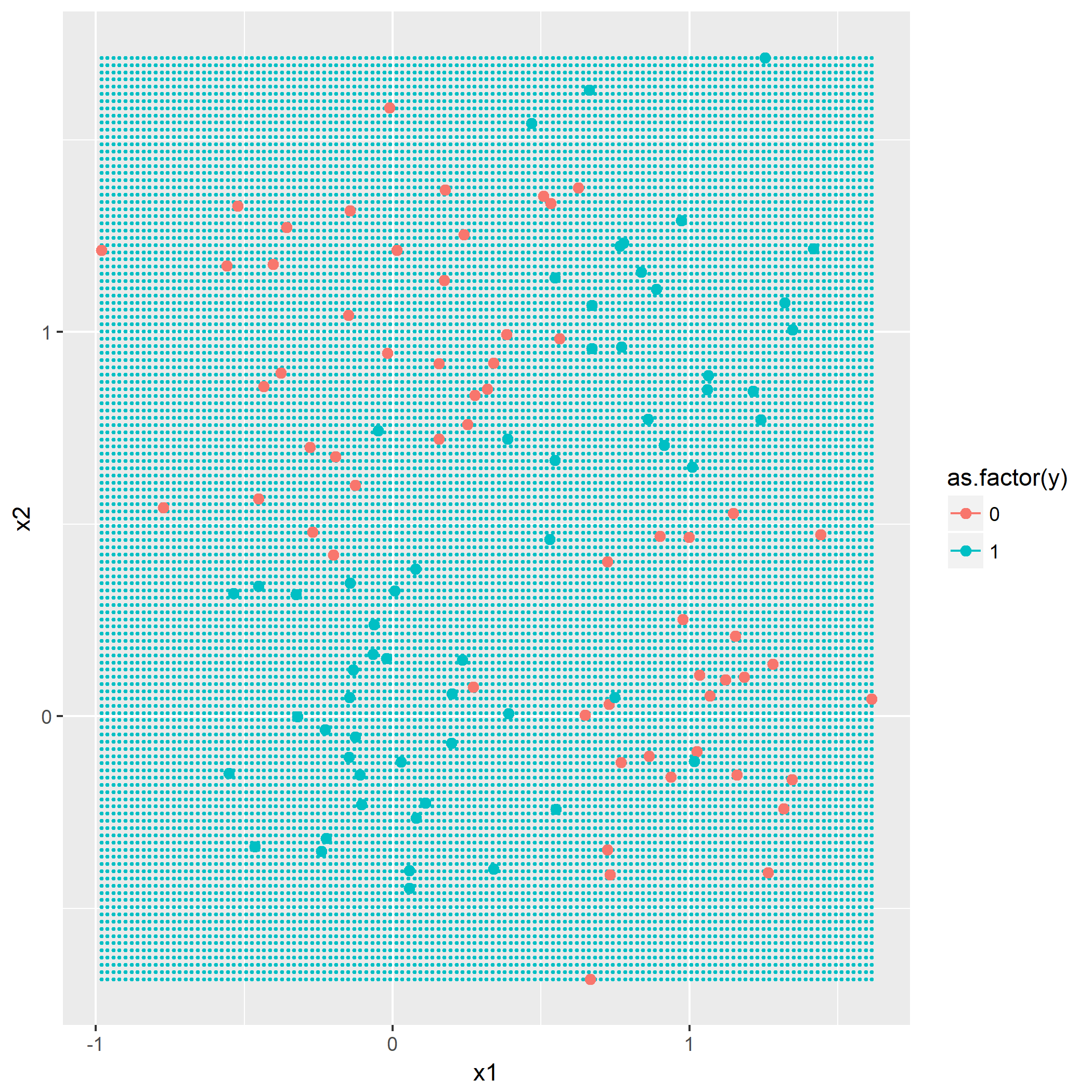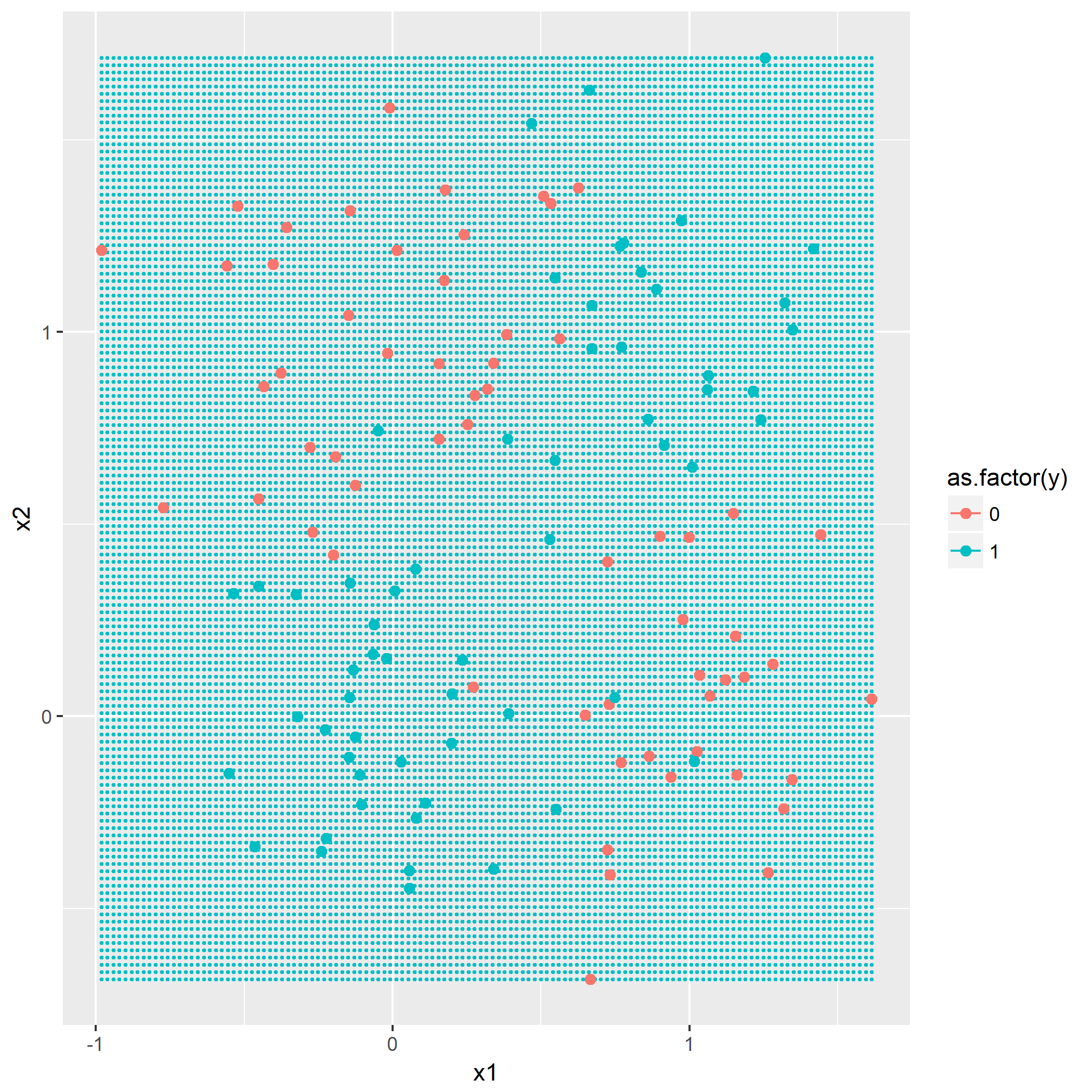The authenticity of host 'github.com (207.97.227.239)' can't be established. RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48. Are you sure you want to continue connecting (yes/no)?
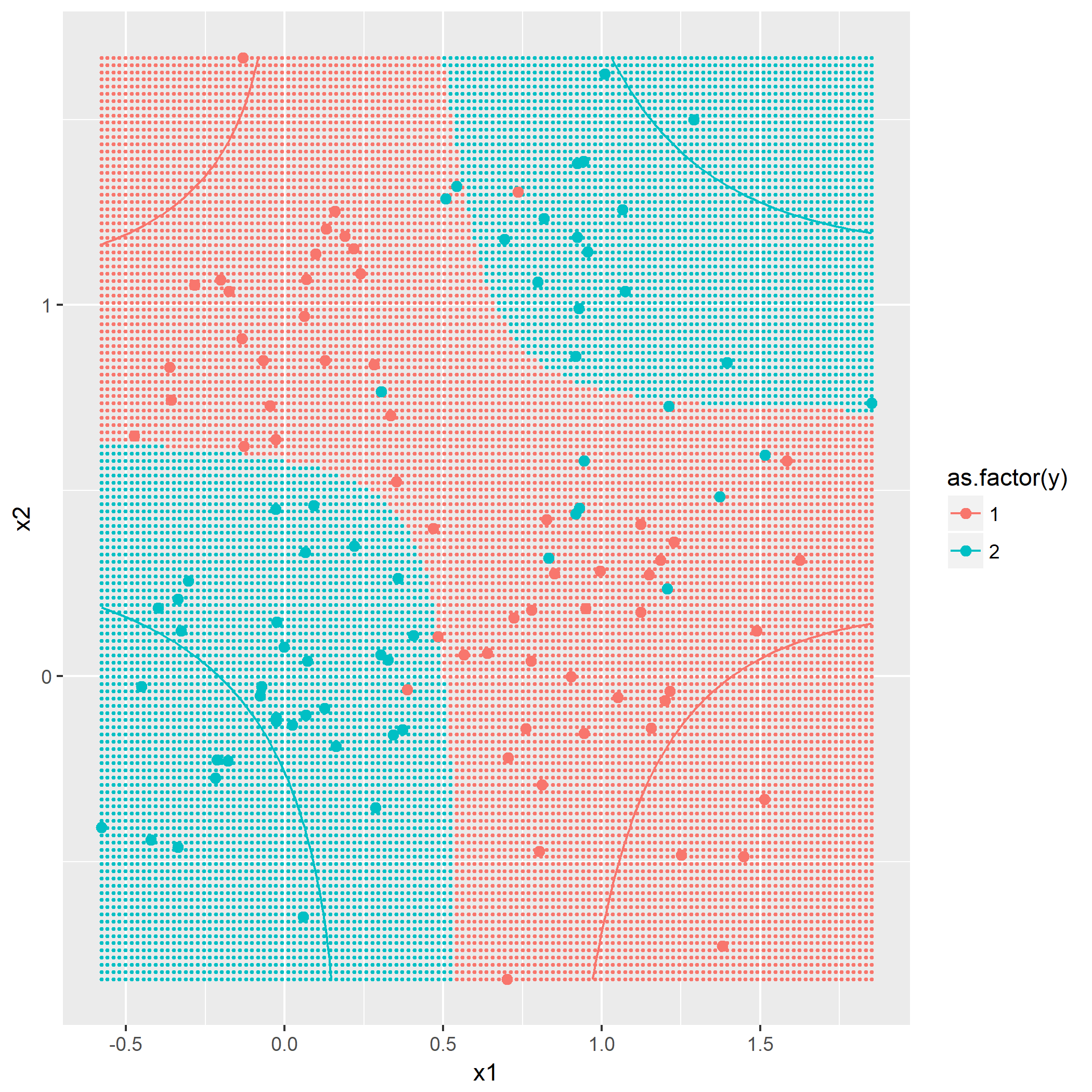
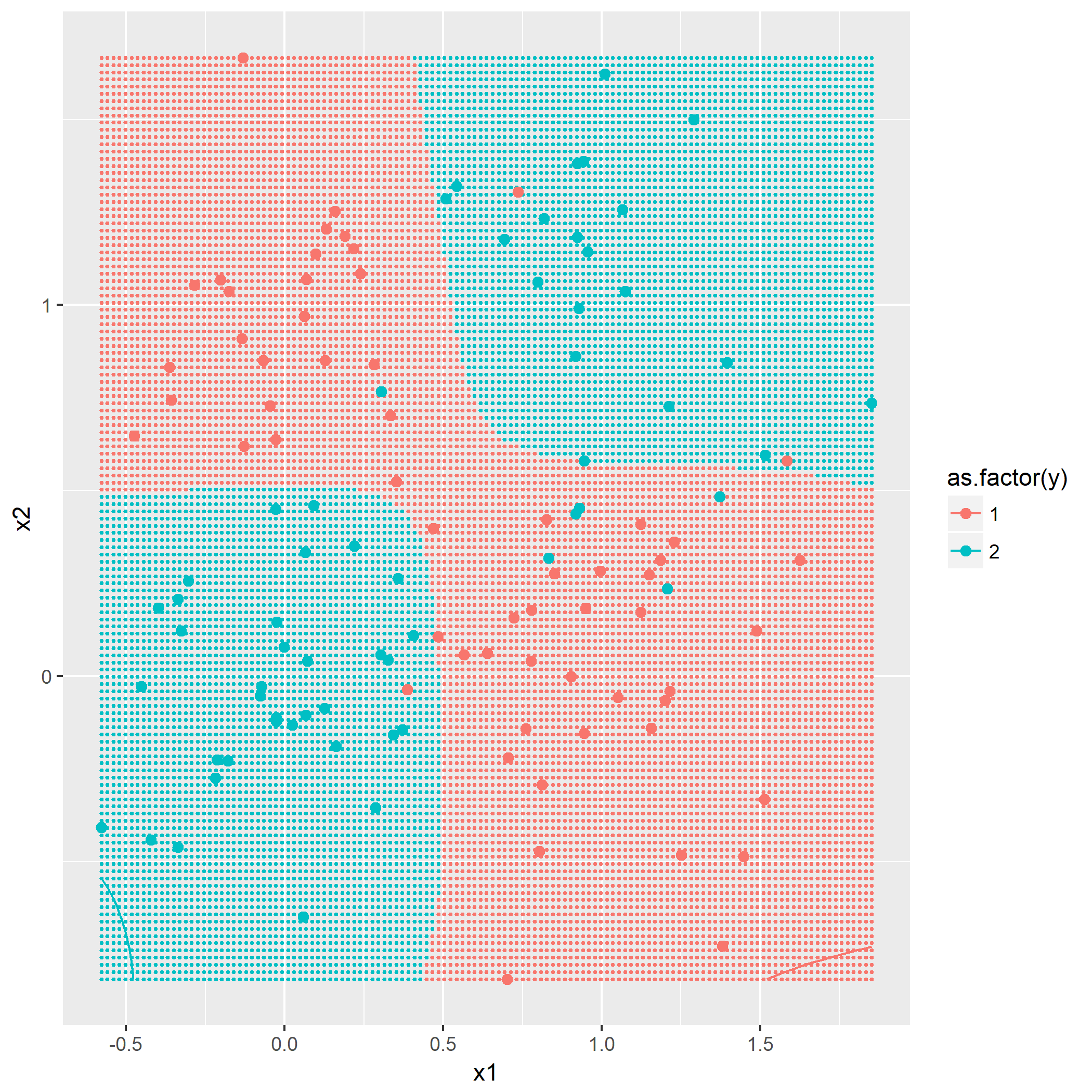
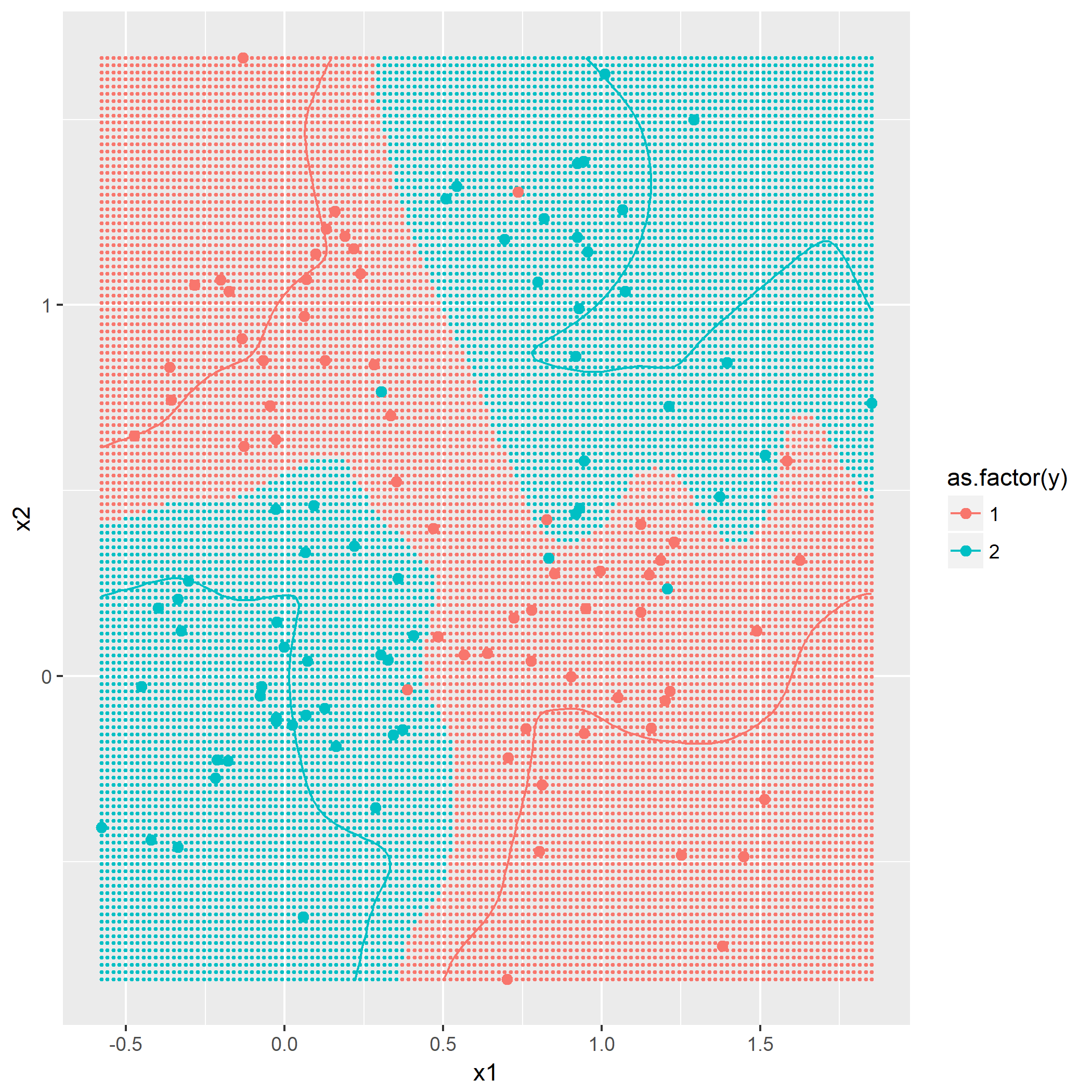
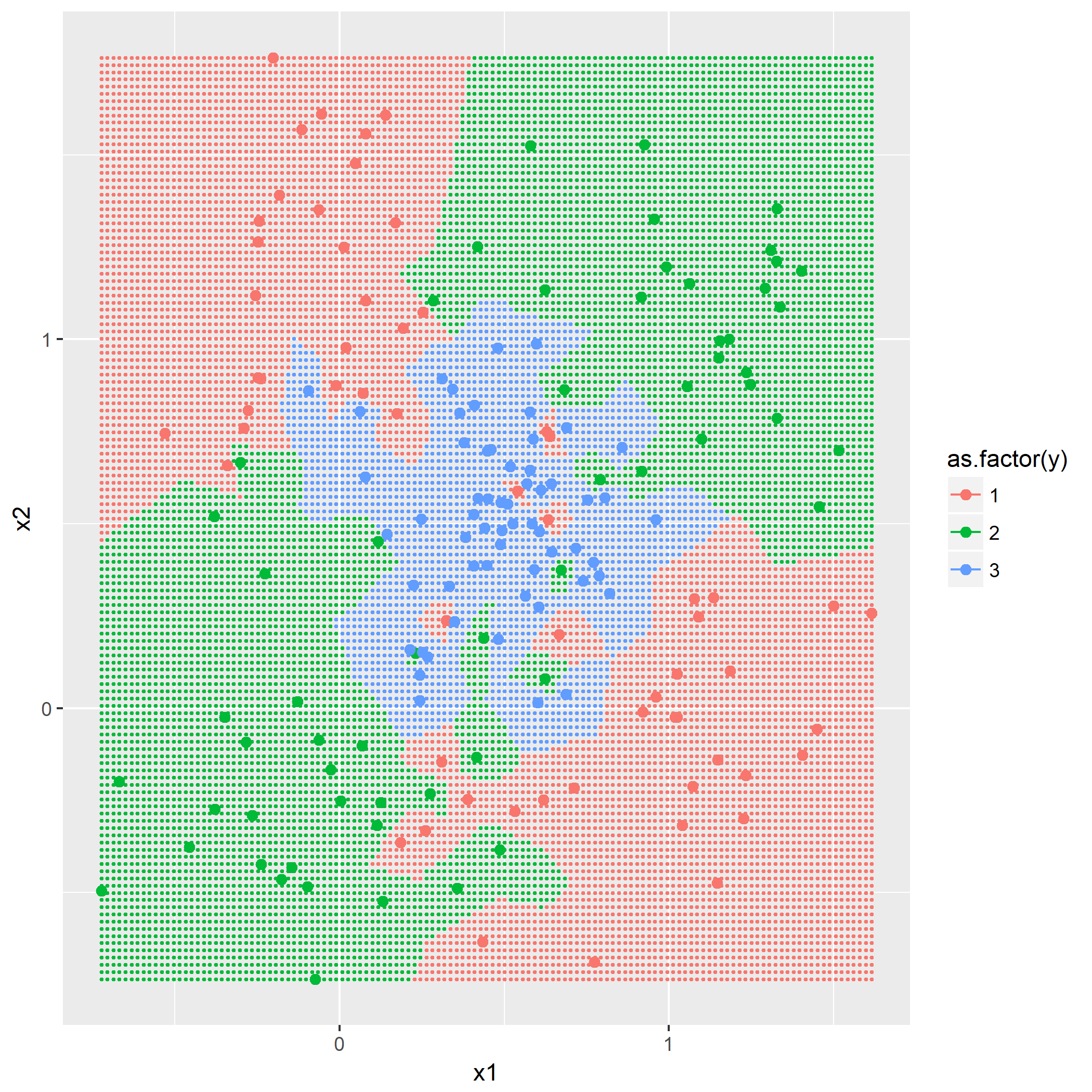
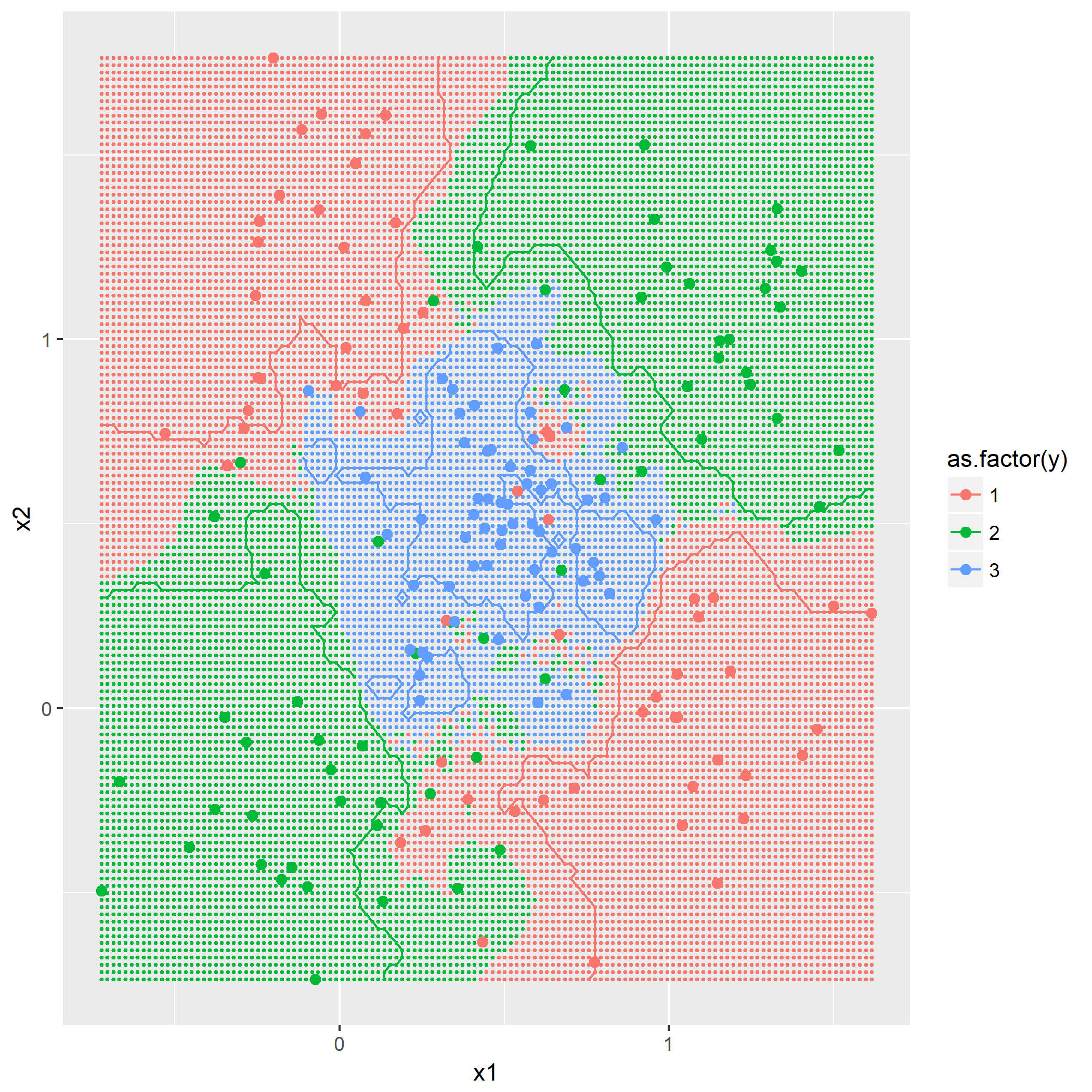
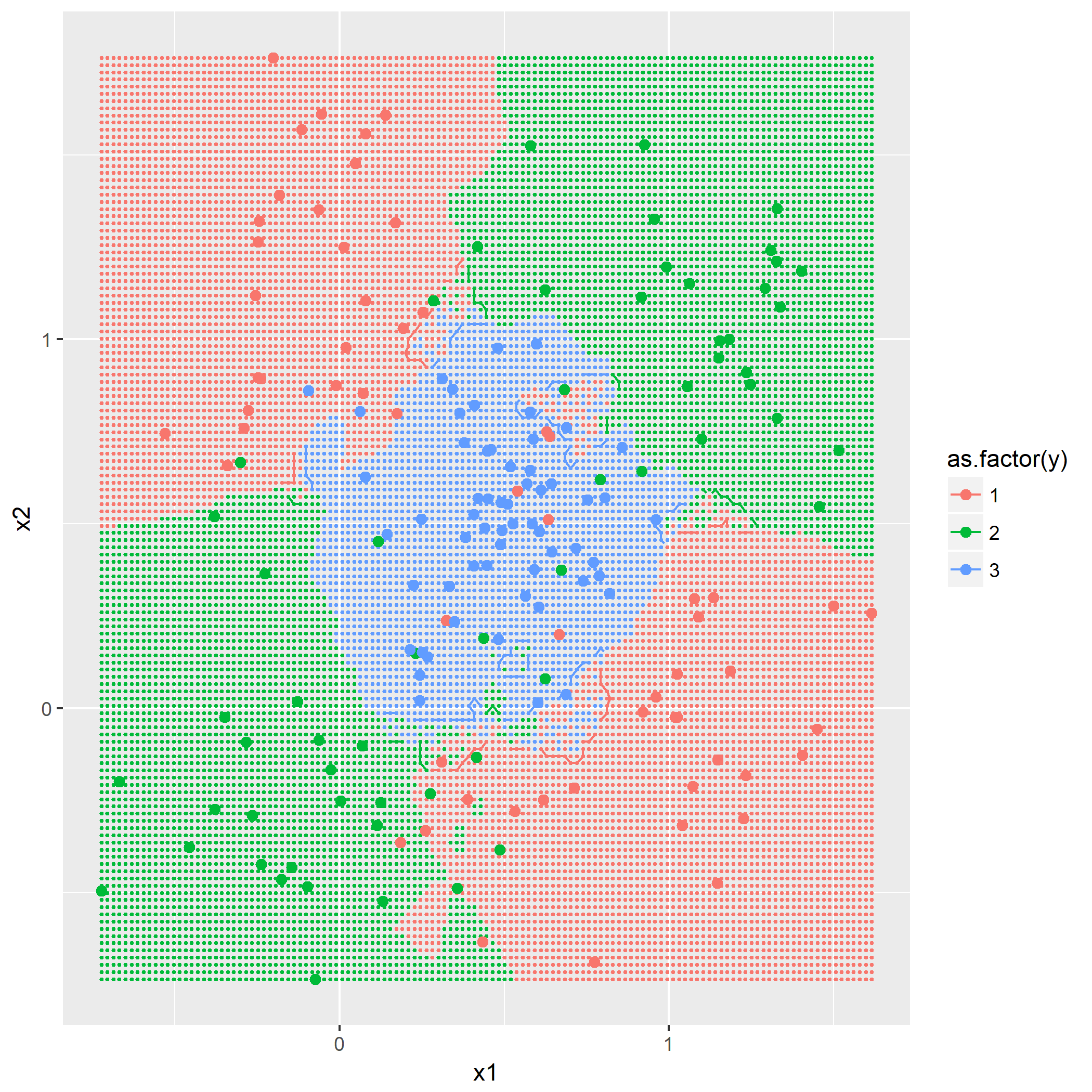
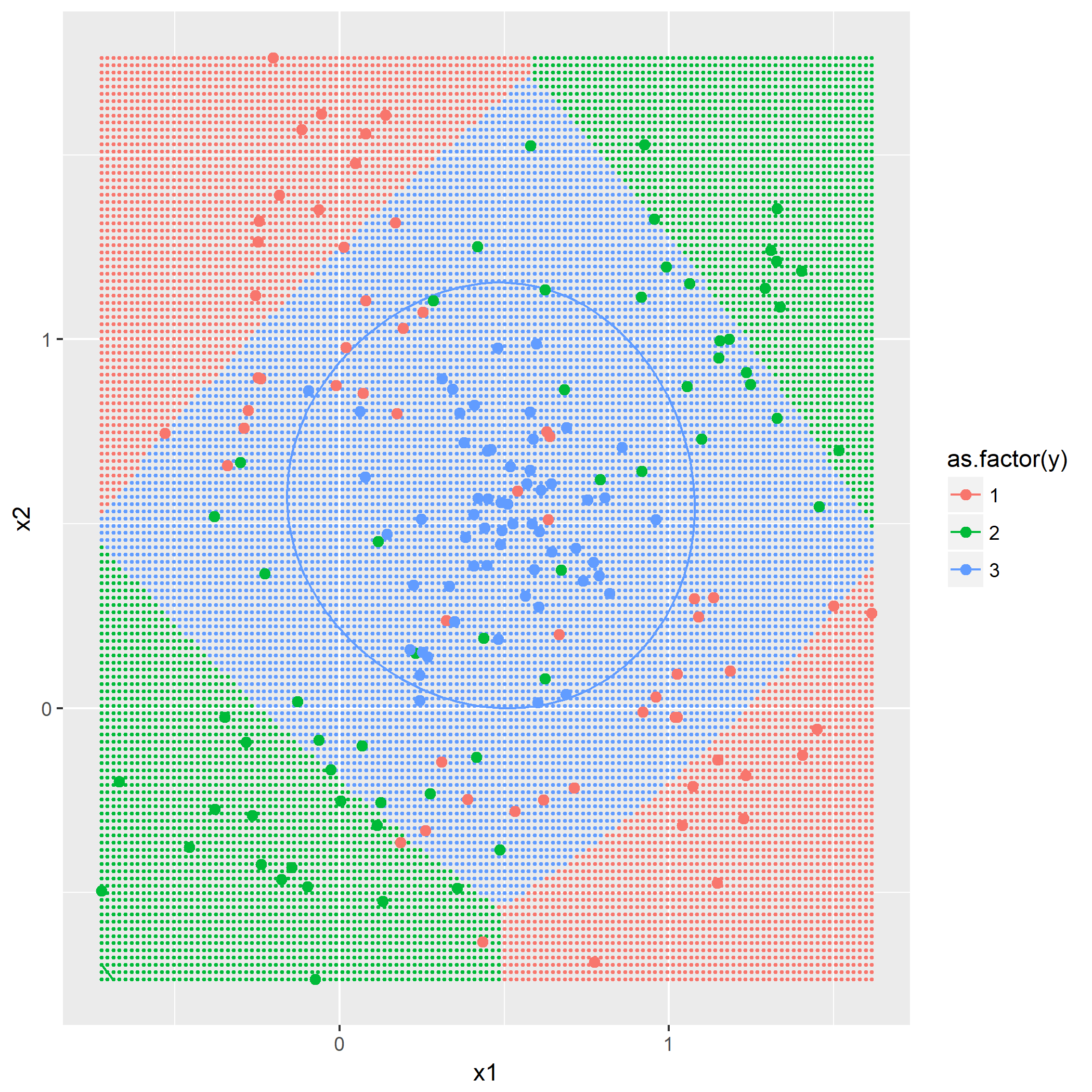
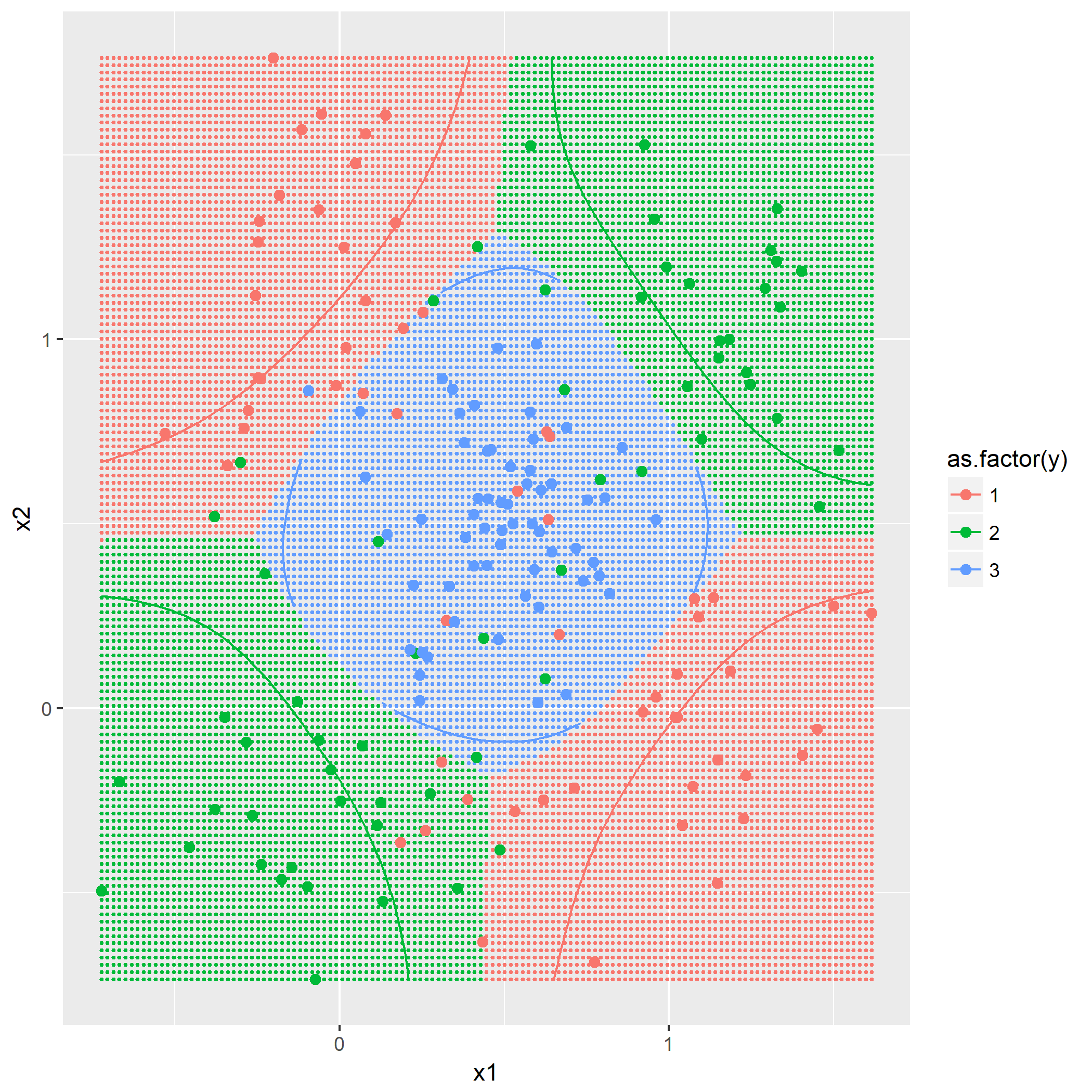
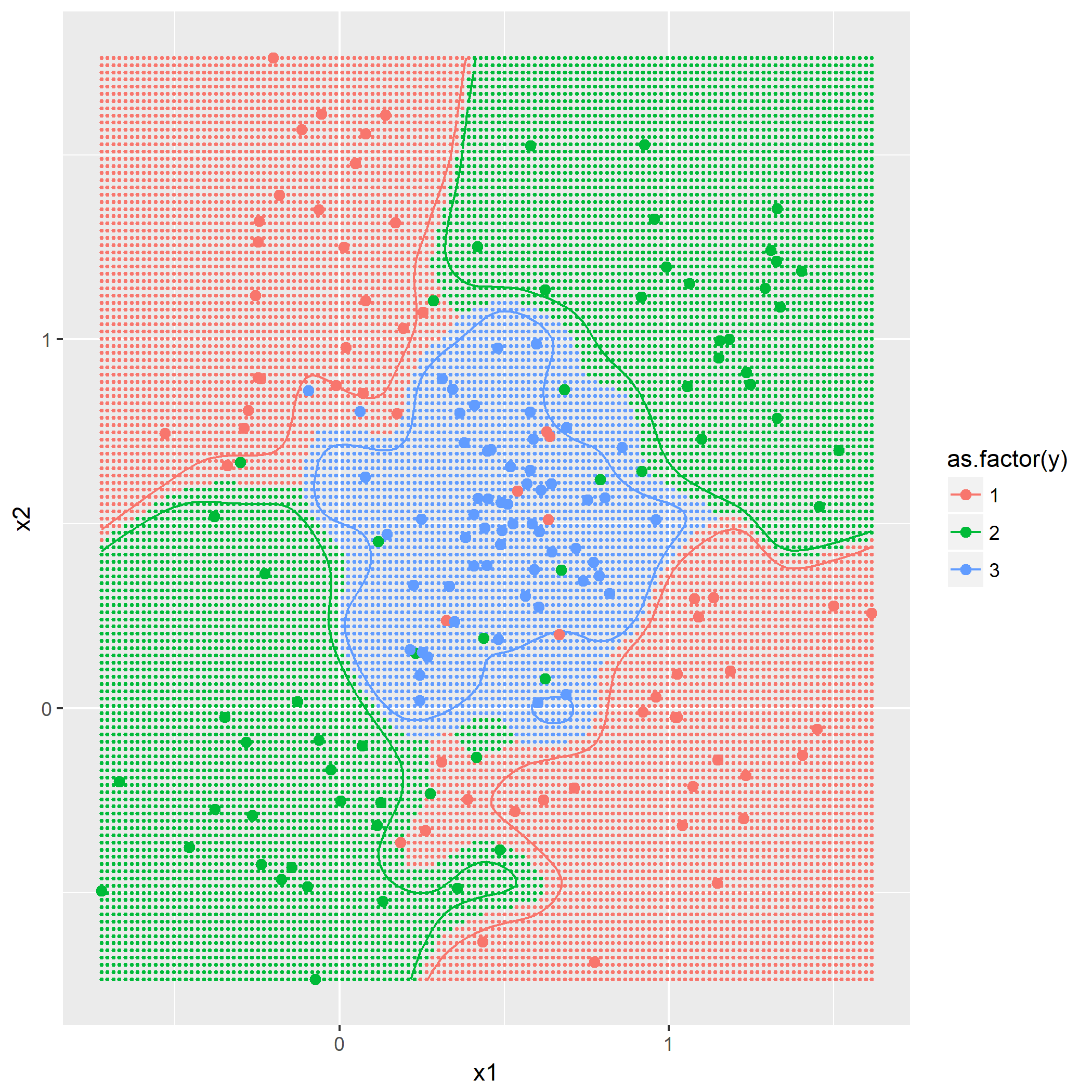
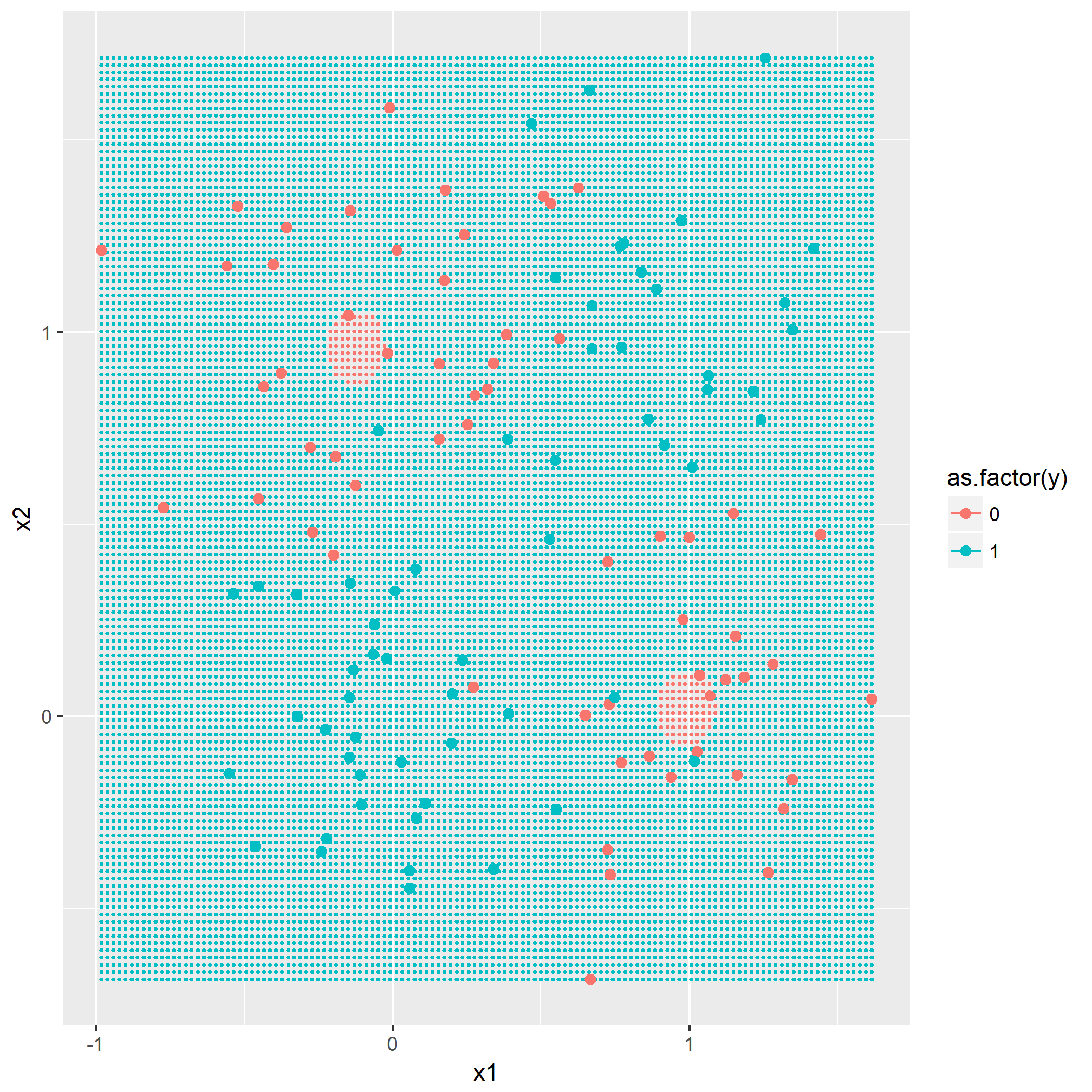
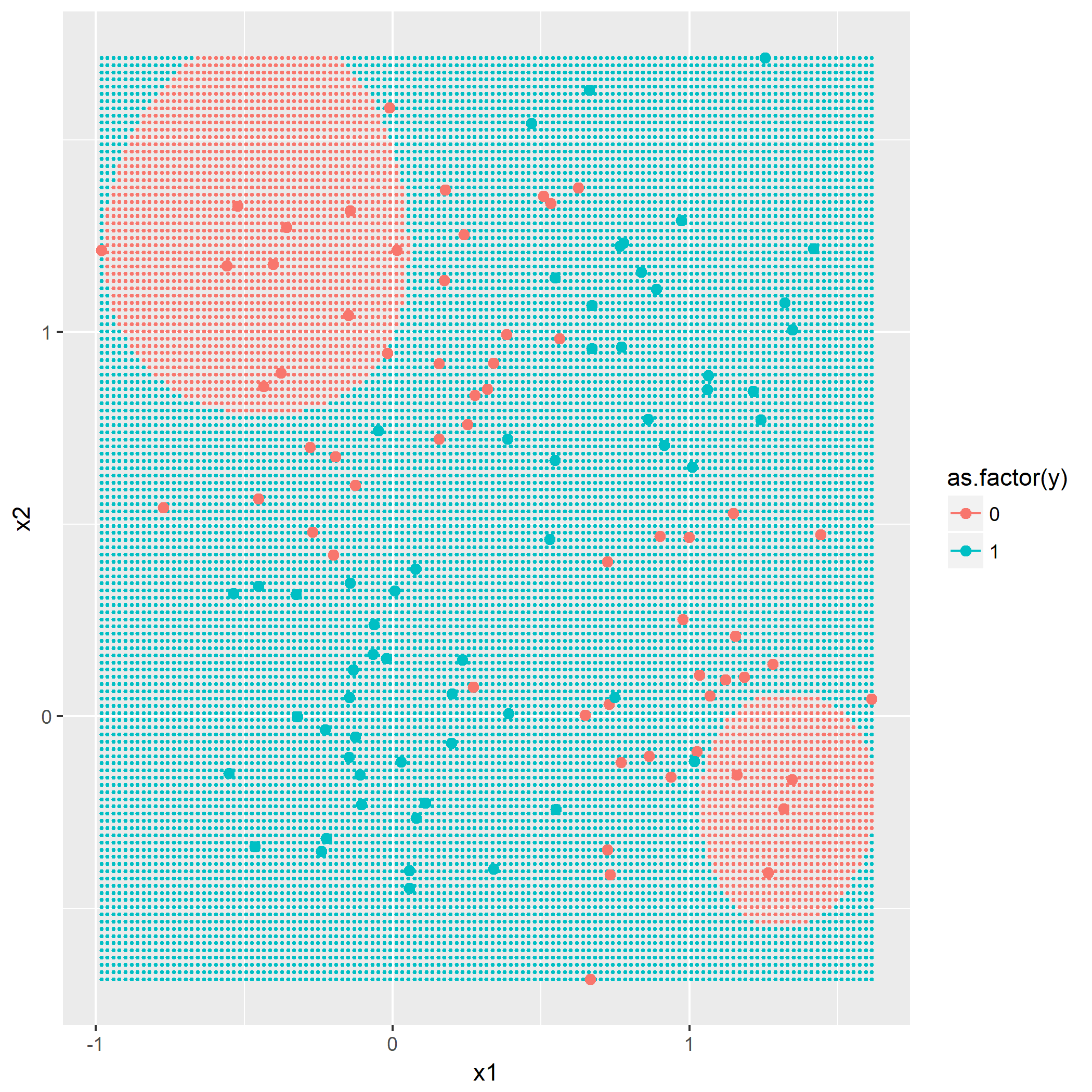
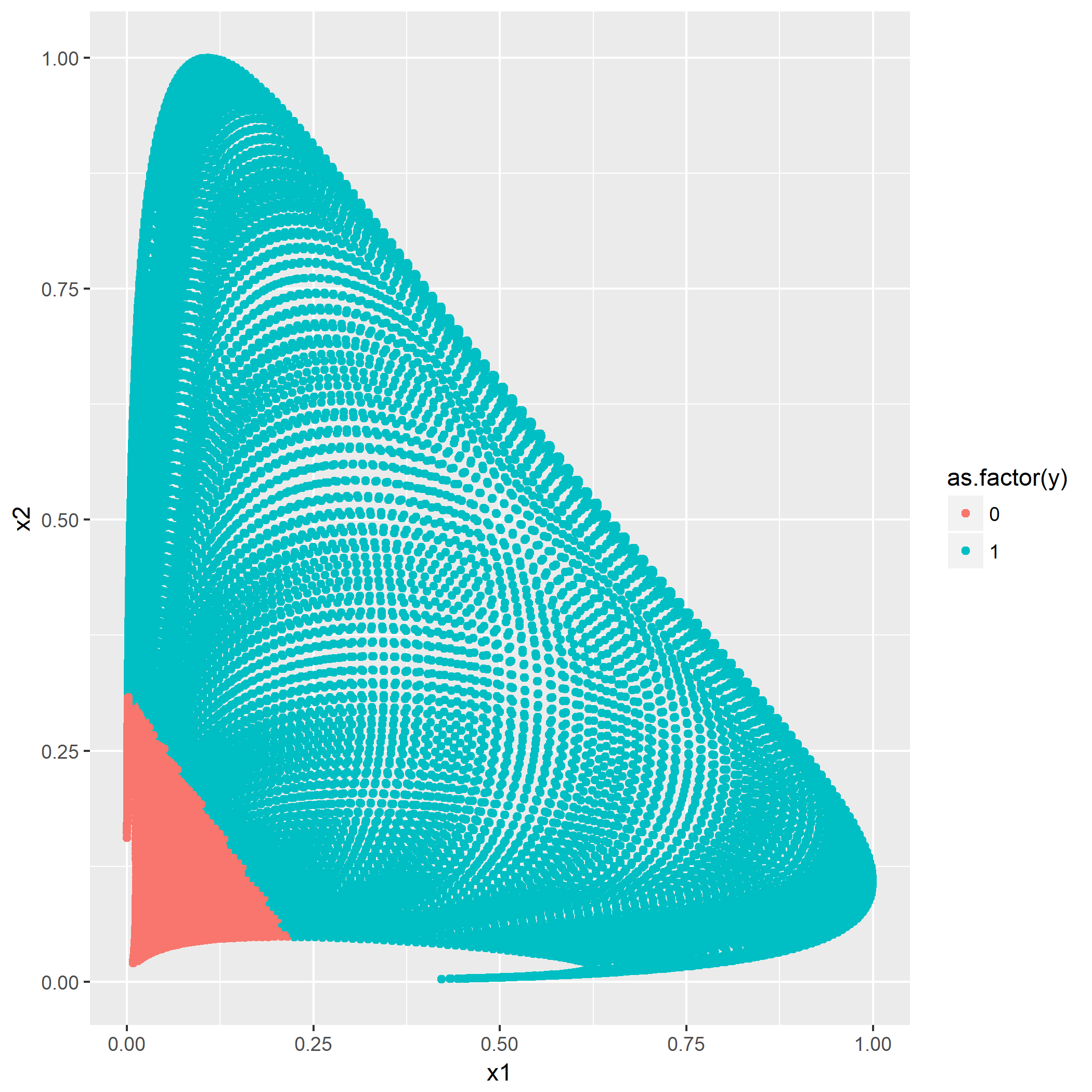
输入: 训练数据集D,特征集A,阈值e 输出: 决策树T if D中所有实例属于同一类C[k] then return new TreeNode(class = C[k]) if A为空集 then 找出D中实例数最多的类C return new TreeNode(class = C) classes = D中各类的统计数 entropy_d = Entropy(classes) for k in 1..A.length cnt = 0 stats_ak = 统计A[k]的取值情况 entropy_ak[k] = 0 for val in A[k] for c in 1..classes.length stats_ak[k][val][c] = 统计取值A[k]=vak,时D[c]的取值情况 entropy_ak[k] = Entropy(stats_ak[k], entropy_d) gain_ak = gain(entropy_d, entropy_ak) 从gain_ak获得最大取值时的k if gain_ak[k] < e then 找出D中实例数最多的类C return new TreeNode(class = C) for val in A[k] 通过val作为识别,将A[k]=val时的实例归到新数据集D_sub[val] A_new[val] = A[k]=val并且去掉A[k]特征后的特征集 T_sub[i] = 递归生成子节点algo(D_sub[val], A_new[val], e) return new TreeNode(child = T_sub)