之前实现了Apriori算法(Apriori算法实现 ),但是该算法存在着不少的算法性能缺陷,例如光是产生候选集都有这么多FP-growth中的FP-tree则是用于压缩这些候选集的存储空间,候选集间会共享相同的元素。例如{A,B,C}和{A,B,D},在Apriori中是单独的记录,而在FP-growth中用树存储,它们会共享{A,B}这个父节点,然后产生{C}和{D}两个子节点,当模式越长的时候,这种压缩方法带来的存储开销优化越明显。
当然为了能够构造这样的树,还要设计额外的算法构建这棵树,一旦FP-tree构建了起来,检索方式就特别方便了,这个例子是典型的牺牲算法复杂度换取存储复杂度的例子。
样例数据集 FP-growth算法过程比Apriori还复杂,需要用一个例子来引导学习者。这里用的是《数据挖掘概念与技术》中的例子。
单号
购物清单
T100
I1,I2,I5
T200
I2,I4
T300
I2,I3
T400
I1,I2,I4
T500
I1,I3
T600
I2,I3
T700
I1,I3
T800
I1,I2,I3,I5
T900
I1,I2,I3
生成FP-tree 第一步与Apriori一样,根据最小支持度产生1项集。按照上述的样例数据,可产生:
项集
支持度计数
{I1}
6
{I2}
7
{I3}
6
{I4}
2
{I5}
2
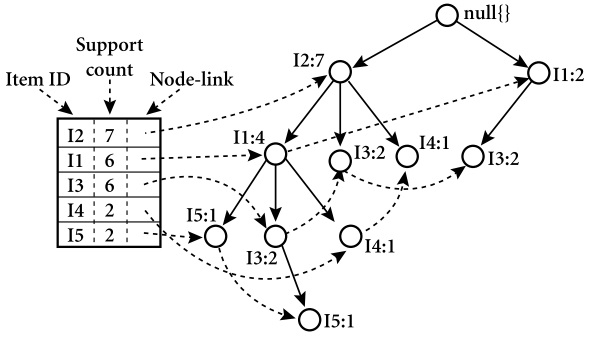
但是FP-growth在此开始就不产生2以上的候选集了。首先按照频数给频繁集排序:{I2:7, I1:6, I3:6, I4:2, I5:2}。以null创建FP-tree的根。
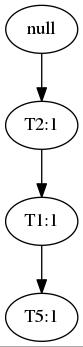
随后扫描每条事务,按照排过序的频繁集读入一条事务。例如读入T100将产生:
再读入T200:
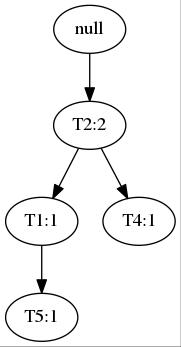
这样,两条事务就共享了一个前缀T2,通过同样的方法,最终构建出一棵FP-tree:
左边的表用于记录频繁集散布在树的位置。
这样生成树之后,只要从树的叶子节点开始,或者从根节点开始,只要设定好支持度阈值或其他参数,都能频繁树中获得目标模式。
伪代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 算法 FP-Growth。使用FP树,通过模式增长挖掘频繁模式。 输入: D: 事务数据库。 min_sup: 最小支持度阈值。 输出: 频繁模式的完全集。 方法: 1.按以下步骤构造FP树: (a)扫描事务数据库D一次。收集频繁项集的集合F和它们的支持度计数。对F按支持度计数降序排序,结果为频繁项列表L。 (b)创建FP树的根节点,以"null"标记它。对于D中每个事务Trans,执行: 选择Trans中的频繁项,并按L中的次序排序。设Trans排序后的频繁项列表为[p|P],其中p是第一个元素,而P是剩余元素的列表。调用insert_tree([p|P], T)。该过程执行情况如下。如果T有子女N使得N.item-name=p.item-name,则N的计数增加1;否则,创建一个新结点N,将其计数设置为1,链接到它的父结点T,并且通过结点链结构将其链接到具有相同item-name的结点。如果P非空,则递归地调用insert_tree(P,N)。 2.FP树的挖掘通过调用FP_growth(FP_tree, null)实现。该实现过程如下。 procedure FP_growth(Tree, α) if Tree 包含单个路径 P then for 路径 P 中结点的每个组合(记作β) 产生模式α ∪ β,其支持度计数support_count等于β中结点的最小支持度计数; else for Tree的表头的每个ai { 产生一个模式β = α ∪ ai,其支持度技术support_count=ai.support_count; 构造β的条件模式基,然后构造β的条件FP树Treeβ; if Treeβ!=Empty Set then 调用FP_growth(Treeβ, β); }
Python实现 先从定义FpTreeNode开始:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class FpTreeNode : def __init__ (self, layer, node_tag='' , val=0 , parent=None , child_list=None ): if child_list is None : child_list = [] self.layer = layer self.node_tag = node_tag self.val = val self.parent = parent self.child_list = child_list def increase_val (self, inc_val=1 ): self.val += inc_val def add_child_node (self, child_node ): self.child_list.append(child_node) def __str__ (self ): return 'Node Name: %s, Value: %d' % (self.node_tag, self.val)
然后定义FpTree:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 class FpTree : def __init__ (self, fre_list ): self.root = FpTreeNode(layer=0 , node_tag='null' ) self.fre_list = fre_list self.lnk_tbl = None def rearrange_ptn_as_fre_list (self, ptn ): rearranged_record = [] for (key, val) in self.fre_list: if key in ptn: rearranged_record.append(key) return rearranged_record def absorb_pattern (self, ptn, cnt ): tree_iter = self.root layer_count = 0 ptn = self.rearrange_ptn_as_fre_list(ptn) for ele in ptn: next_node = None for child_node in tree_iter.child_list: if child_node.node_tag == ele: child_node.increase_val(cnt) next_node = child_node break if next_node is None : next_node = FpTreeNode(layer=layer_count + 1 , node_tag=ele, val=cnt, parent=tree_iter) tree_iter.add_child_node(next_node) tree_iter = next_node layer_count += 1 def gen_link_tbl (self ): link_tbl = {} for (key, val) in self.fre_list: link_tbl[key] = [val] queue = [] for node in self.root.child_list: queue.append(node) while len (queue) > 0 : node = queue[0 ] queue.pop(0 ) for child_node in node.child_list: queue.append(child_node) link_tbl[node.node_tag].append(node) return link_tbl def gen_prefix_paths (self, key, update_lnk_tbl=False ): if self.lnk_tbl is None or update_lnk_tbl: self.lnk_tbl = self.gen_link_tbl() prefix_paths = {} for node in self.lnk_tbl[key][1 ::]: node_iter = node.parent prefix_path = set () while node_iter.node_tag != 'null' : prefix_path.add(node_iter.node_tag) node_iter = node_iter.parent if len (prefix_path) > 0 : prefix_paths[frozenset (prefix_path)] = node.val return prefix_paths def is_empty (self ): return True if len (self.root.child_list) < 1 else False
生成FP-Tree:
1 2 3 4 5 6 7 8 9 10 11 12 13 def gen_fp_tree (dataset, min_sup=1 ): frequent_list = find_frequent_1_itemsets(dataset, min_sup) frequent_list = sorted (frequent_list.items(), key=lambda d: d[1 ], reverse=True ) fp_tree = FpTree(frequent_list) for record, cnt in data_set.items(): fp_tree.absorb_pattern(record, cnt) return fp_tree
生成了树之后,就可以调用FP_growth生成频繁模式了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def FP_growth (fp_tree, min_sup=1 , prefix=None , fre_item_list=None ): if fre_item_list is None : fre_item_list = {} if prefix is None : prefix = set () for base_ptn, val in fp_tree.fre_list: new_fre_set = prefix.copy() new_fre_set.add(base_ptn) fre_item_list[frozenset (new_fre_set)] = val cond_ptn_bases = fp_tree.gen_prefix_paths(base_ptn) cond_fp_tree = gen_fp_tree(cond_ptn_bases, min_sup) if not cond_fp_tree.is_empty(): FP_growth(cond_fp_tree, min_sup, new_fre_set, fre_item_list) return fre_item_list
代码中涉及到的数据加载以及产生1频繁项集的代码都与Apriori算法实现 一致,故本文就没有写上。
在这里要说明的是,在递归向下的时候,条件模式树会被不断地生成,以及生成去掉了前缀元素后的子树,因为暂时没有办法解决在不生成新的条件模式树的情况下,让下一层递归能够正确处理更新后的数据。所以笔者这里是一个可以优化的地方。
至此,FP-growth实现完毕。