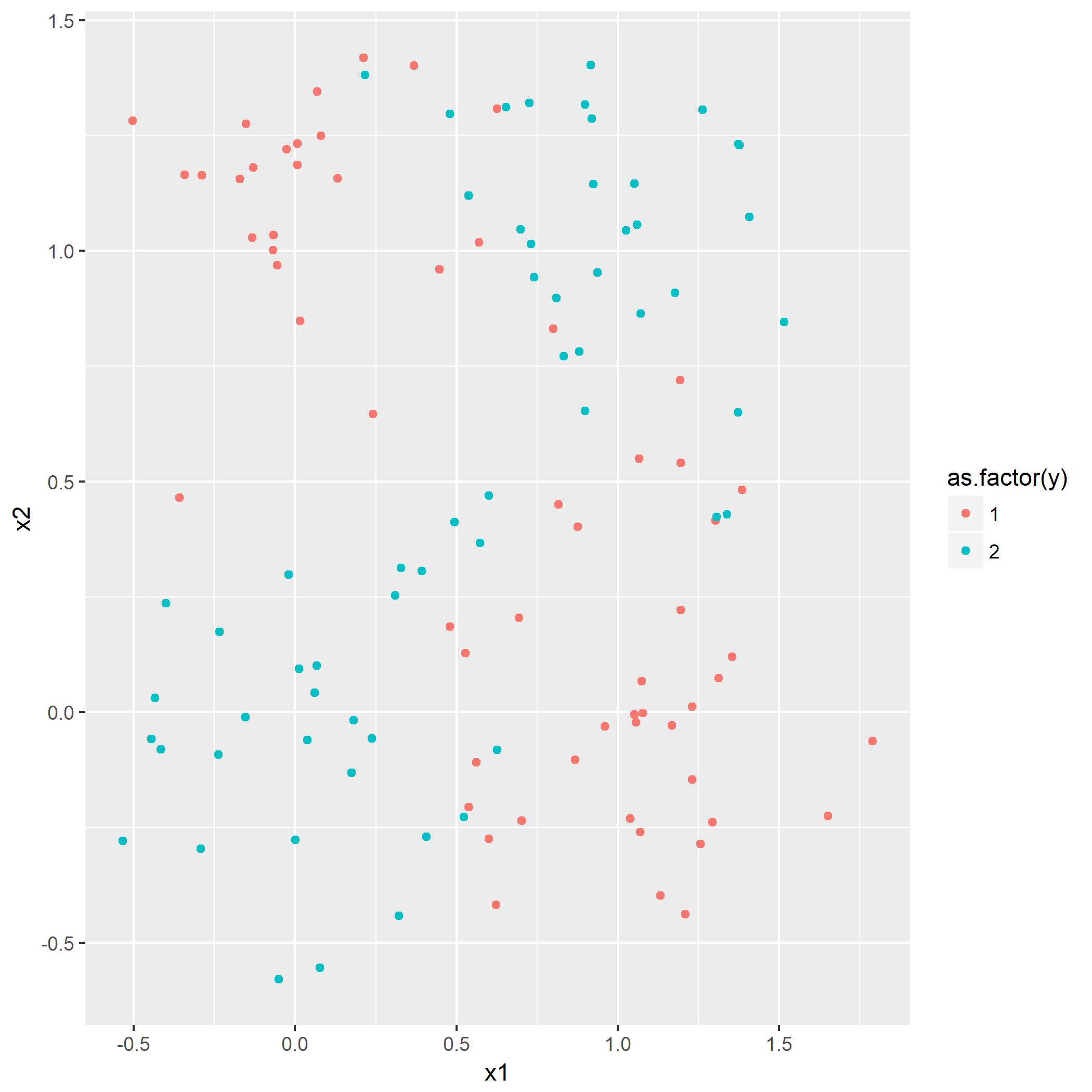
题目7.1 - 训练数据的准备
目的是产生一个典型的XOR问题的数据分布,通过如下的公式产生:
其中
根据规则产生y=0以及y=1各60组的数据分布:
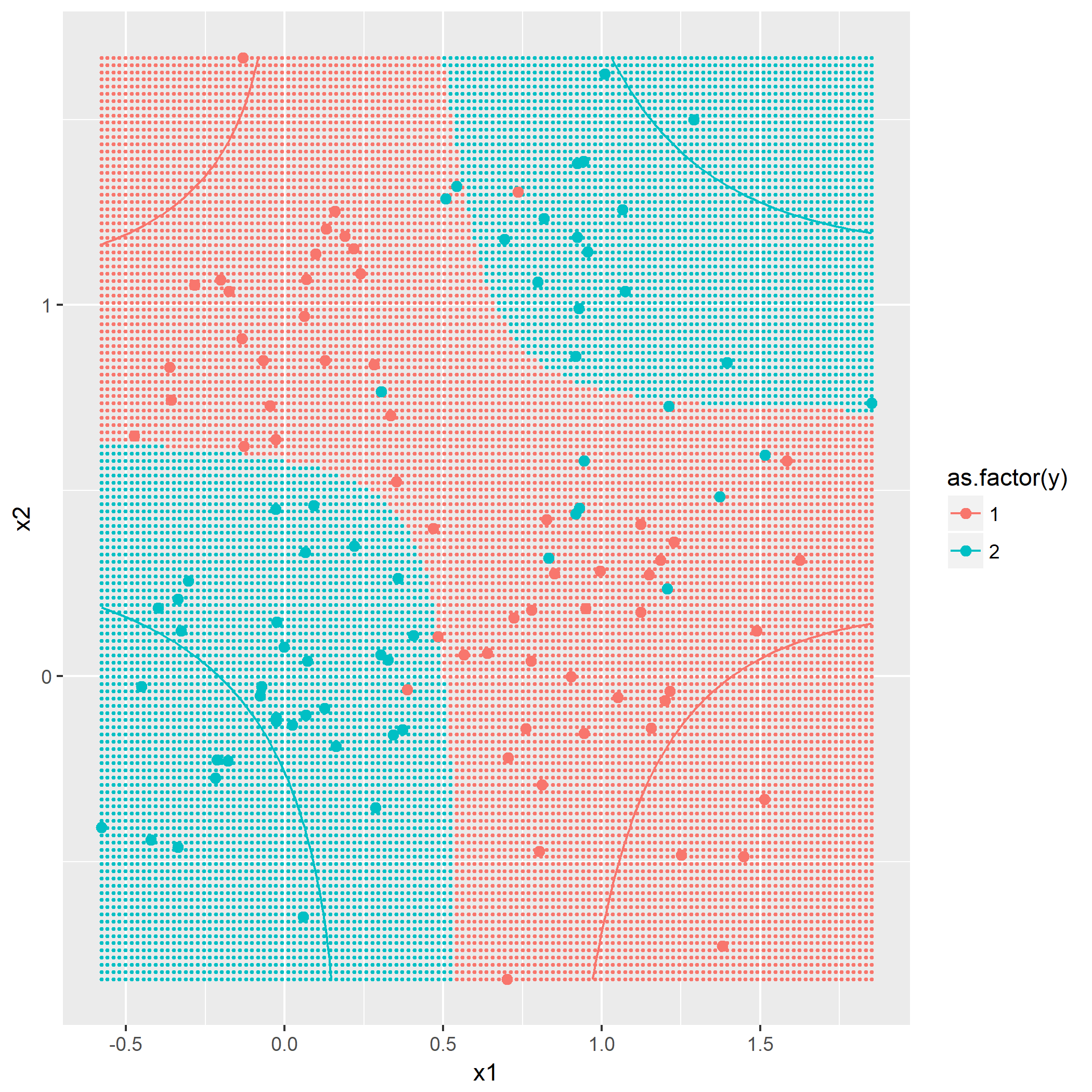
题目7.2 - k近邻
kNN算法概念,令k=1,3,5,描绘出决策边界,没有什么技巧,就是暴力计算,用密集的点表示出决策边界:
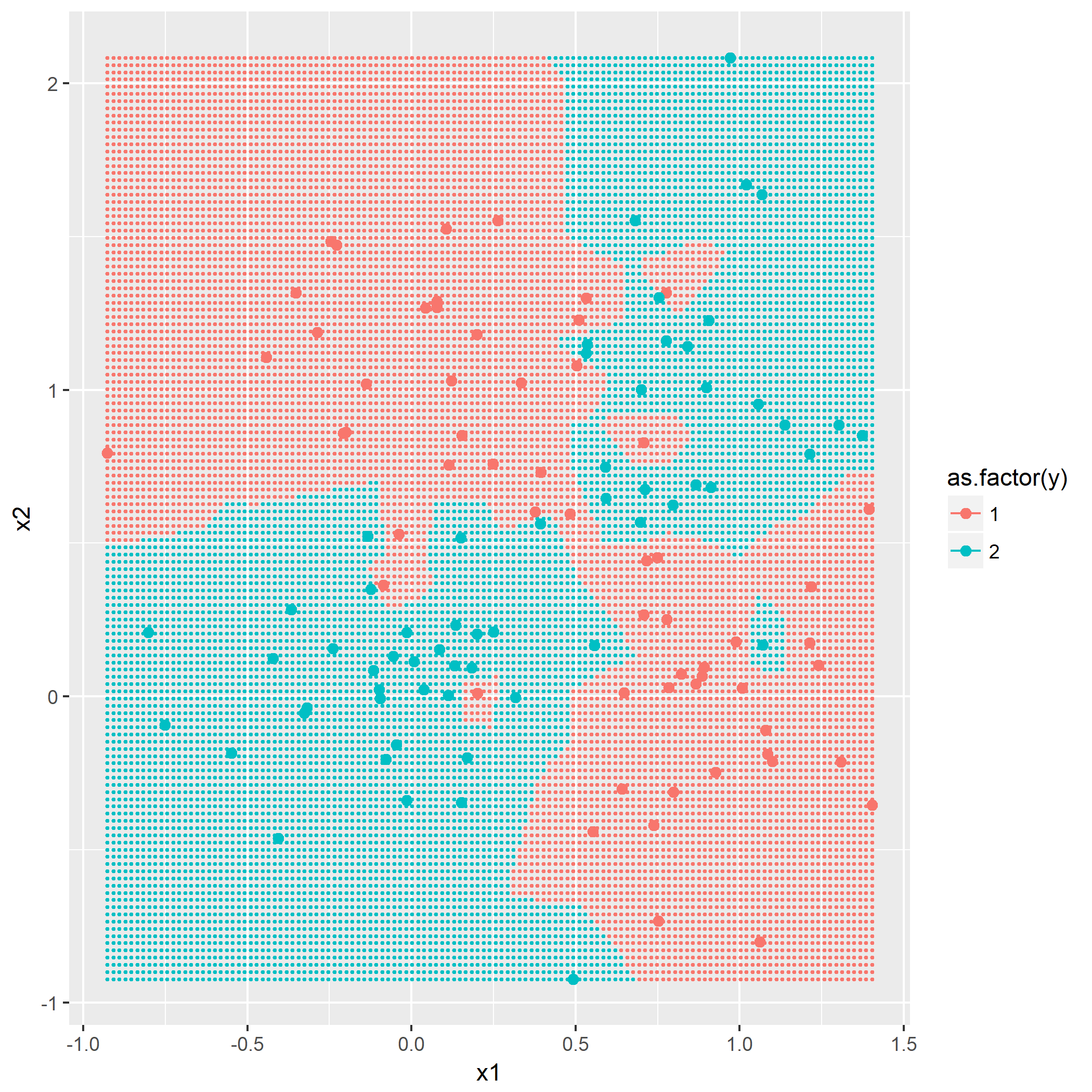
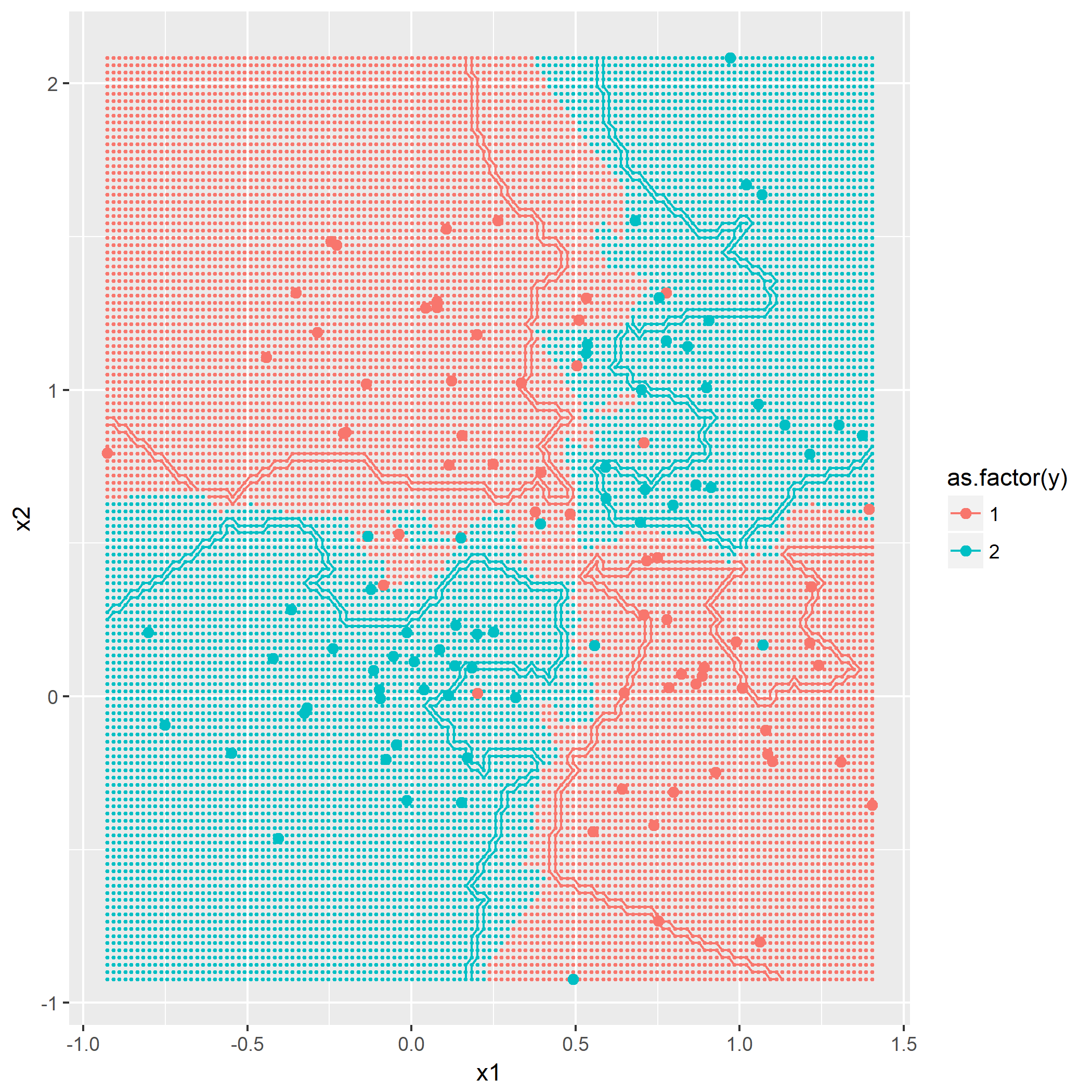
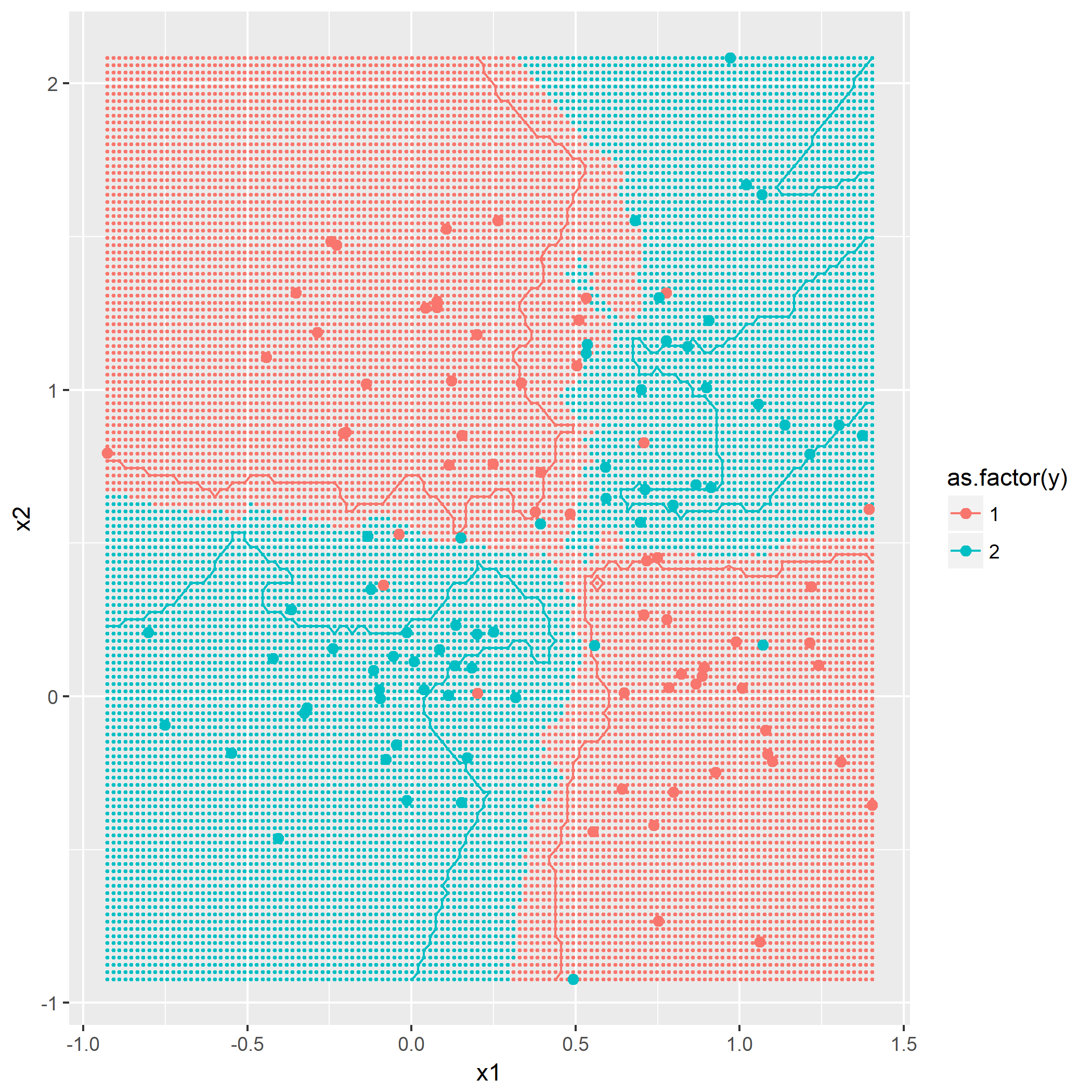
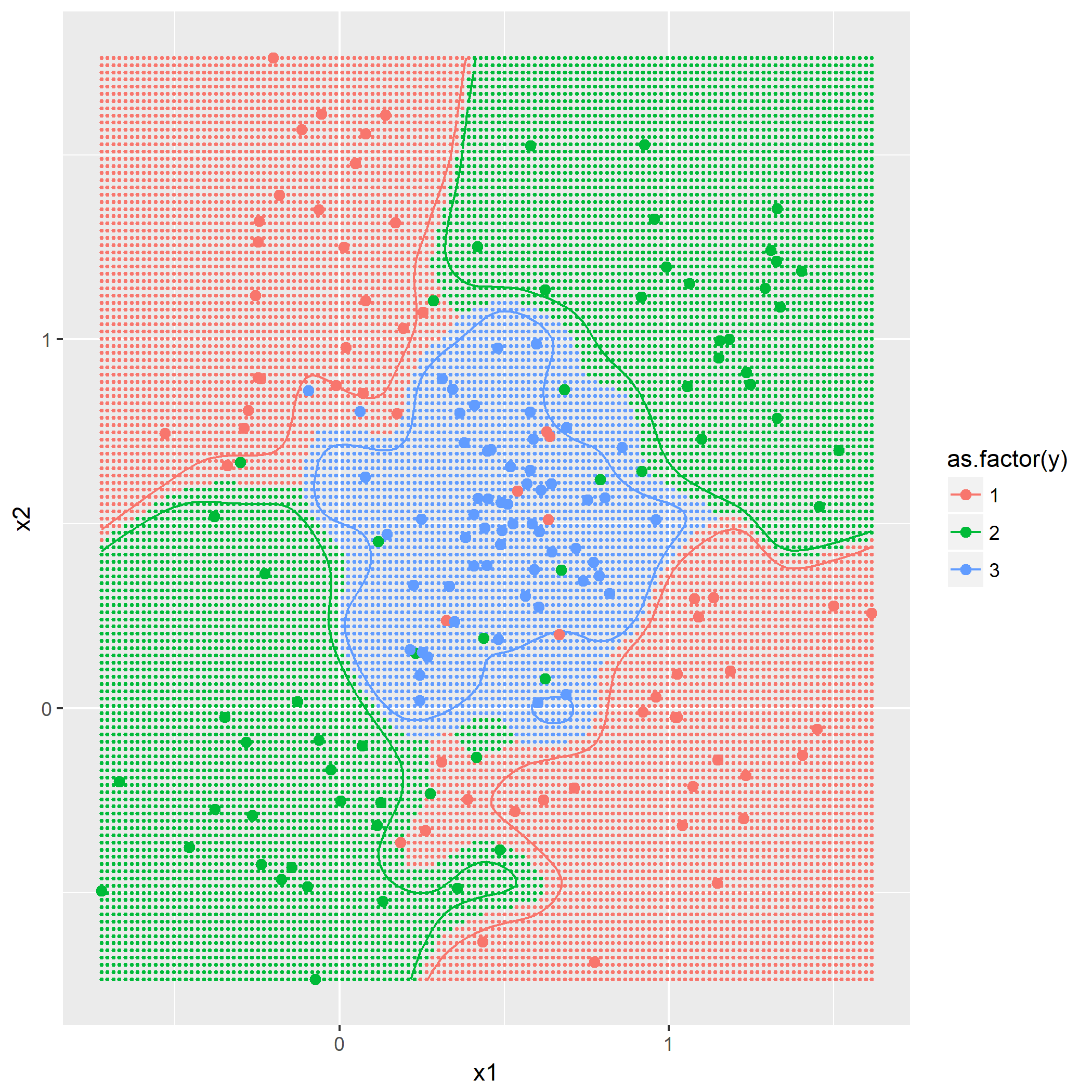
题目7.3 - “Parzen window”分类器
基于欧氏范数的高斯窗口函数:
即根据作为训练集的点与将被预测的点的距离通过此函数计算出影响权重,最后得出哪个类别的权重最大。
利用同样作图方法,画出
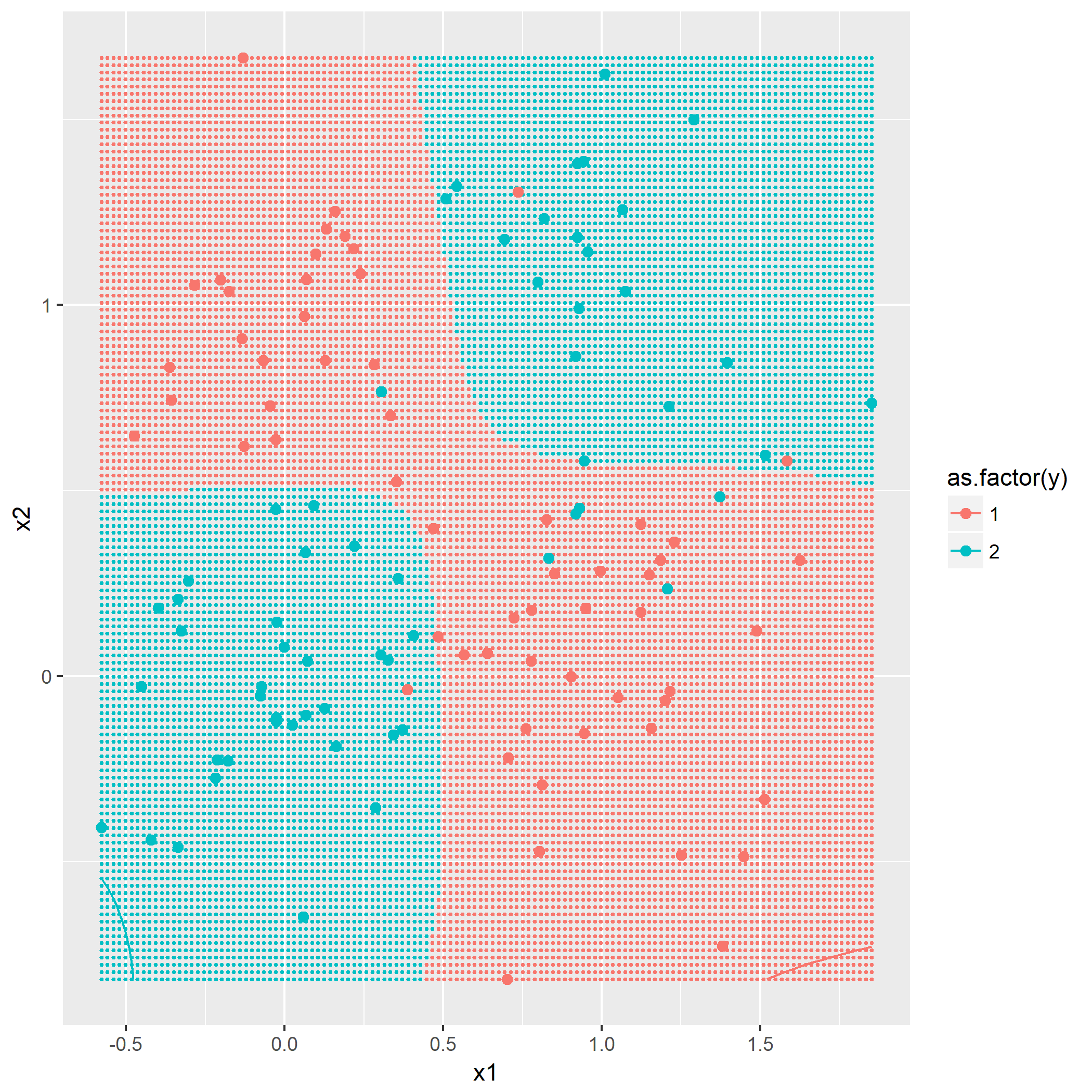
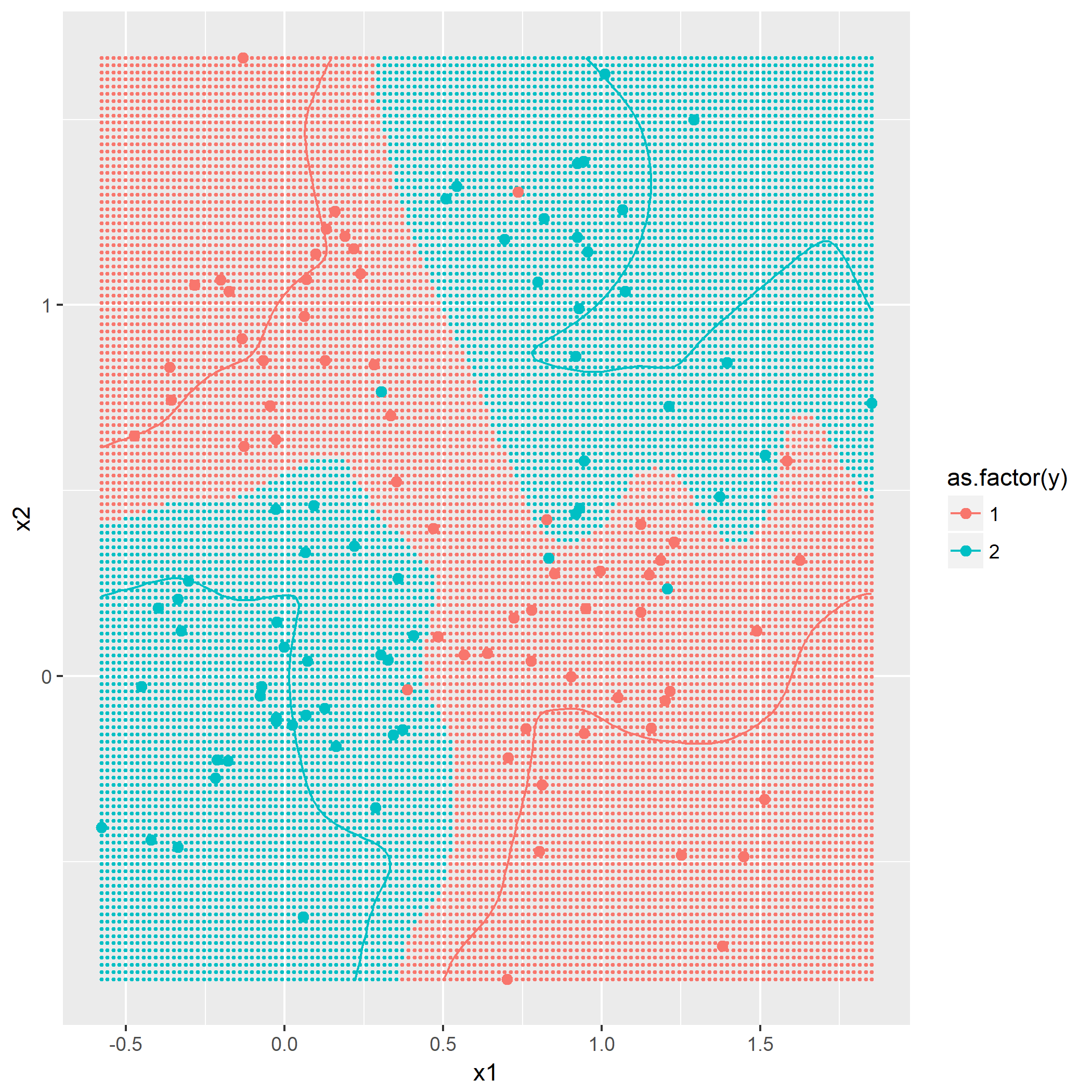
可以看到
第二问是添加第三个类别,根据
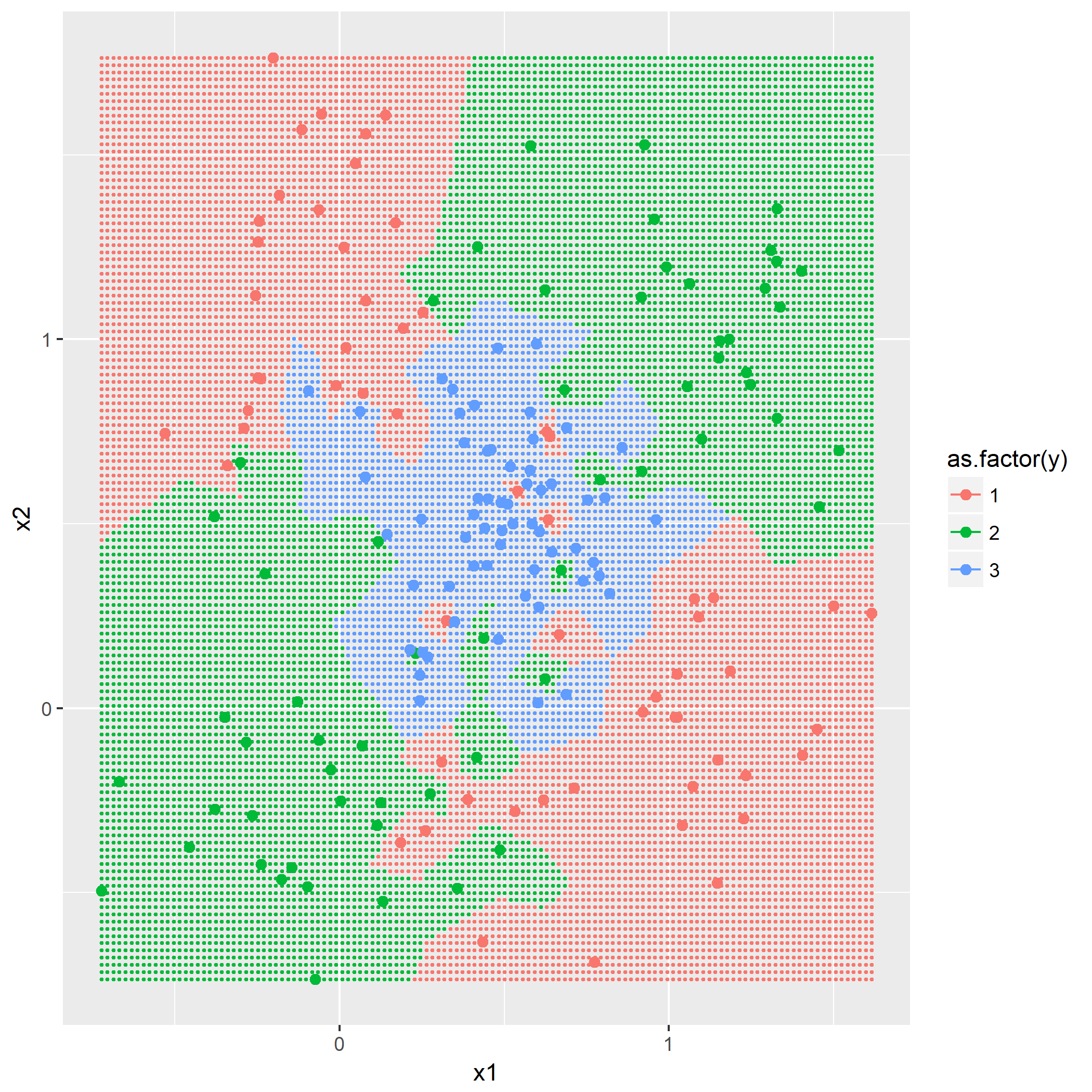
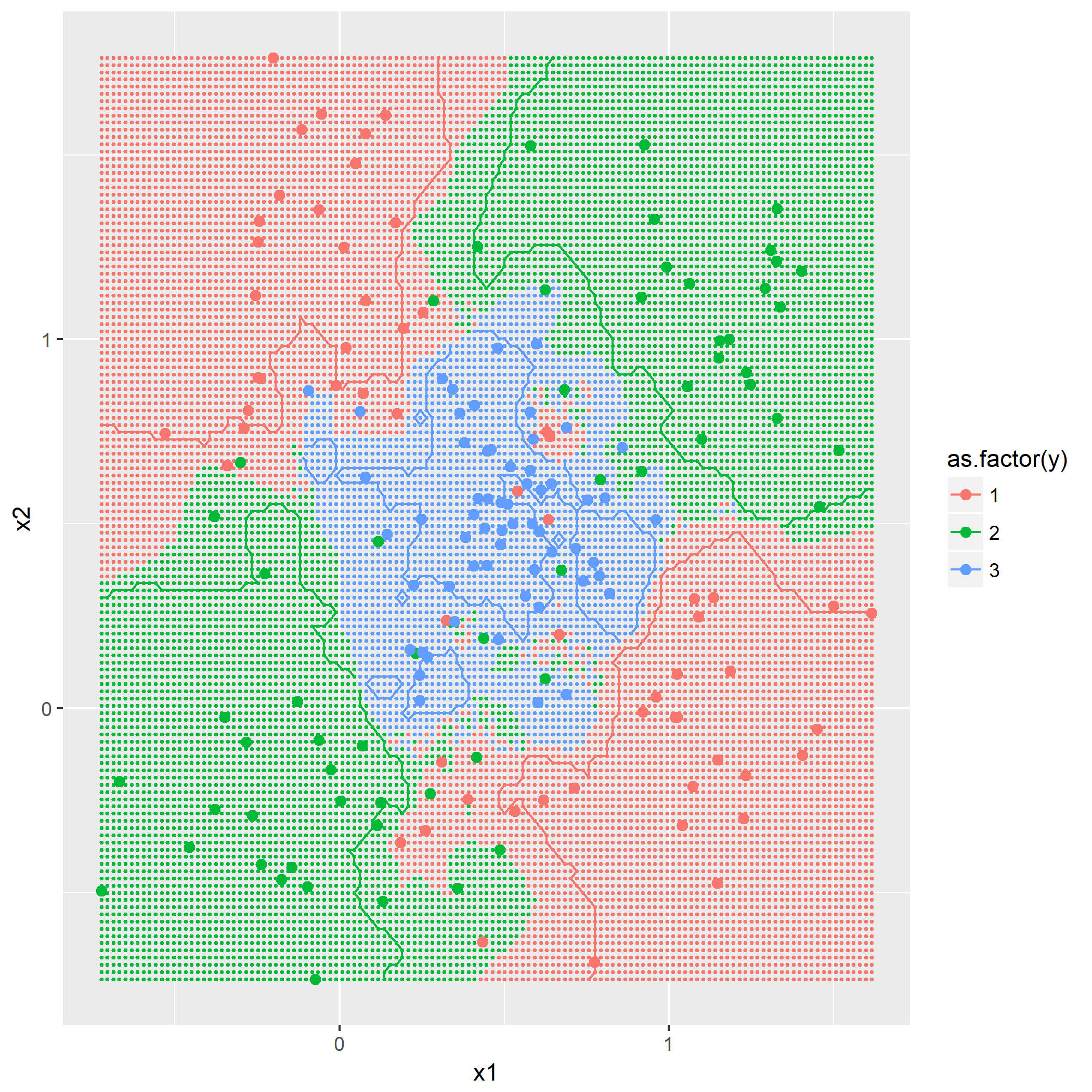
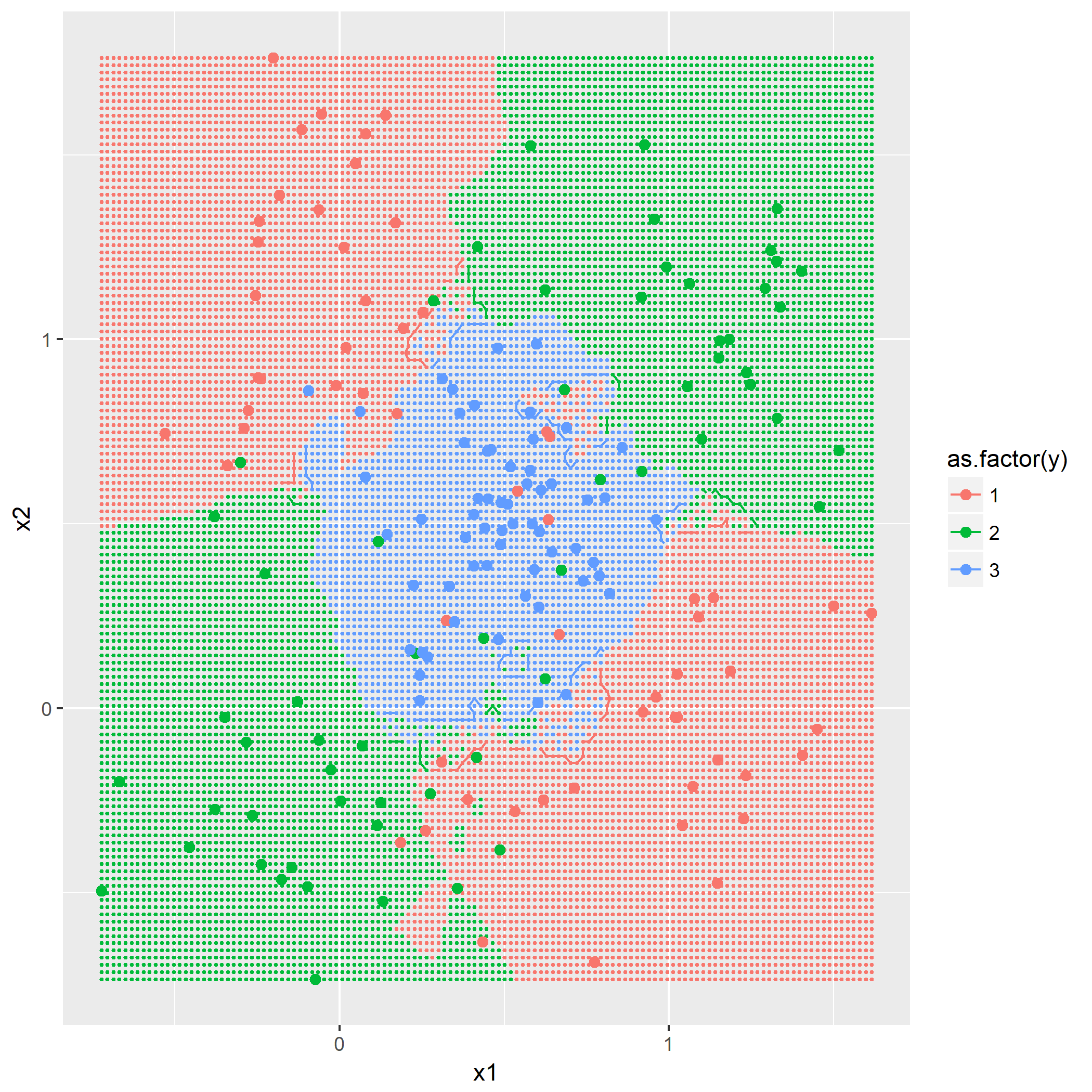
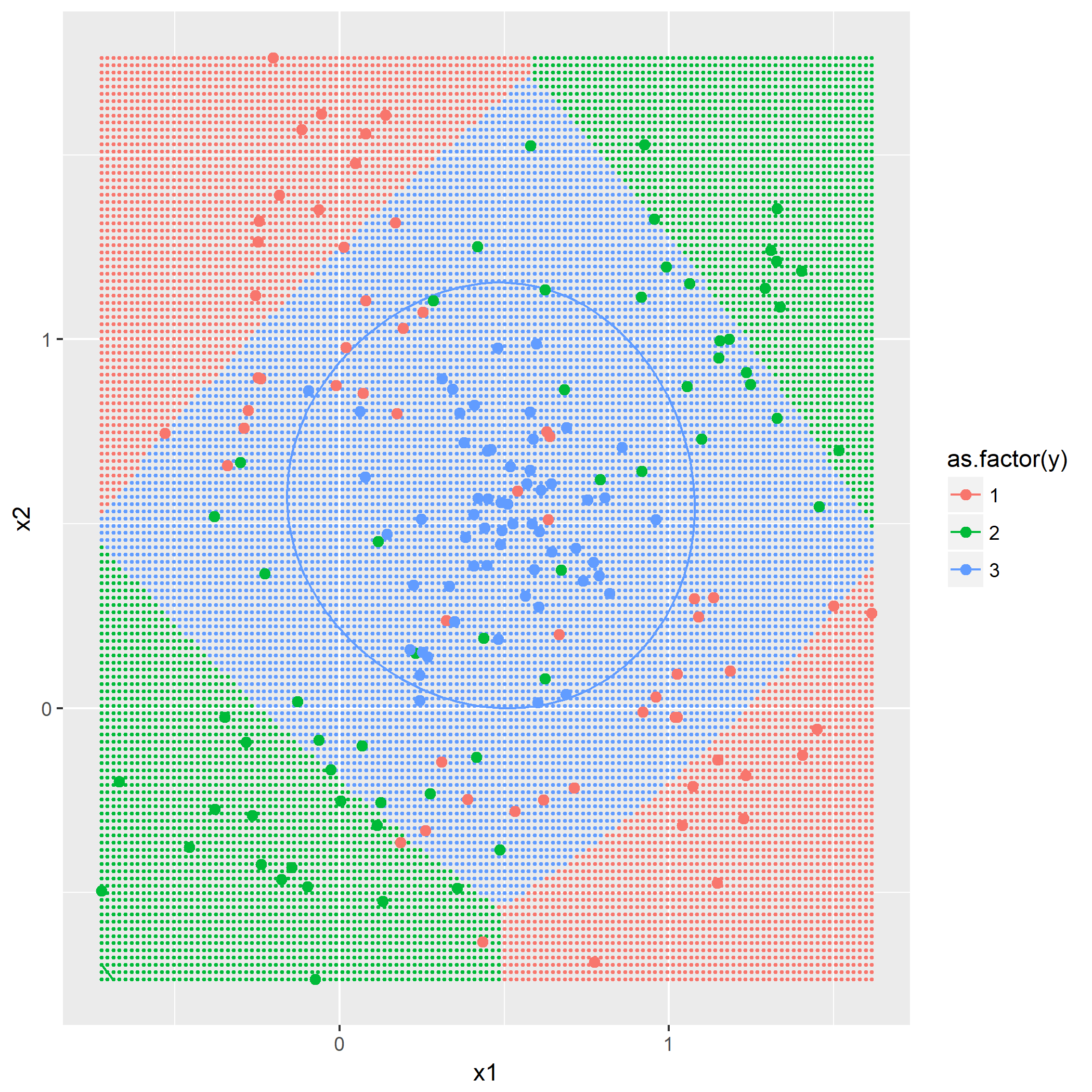
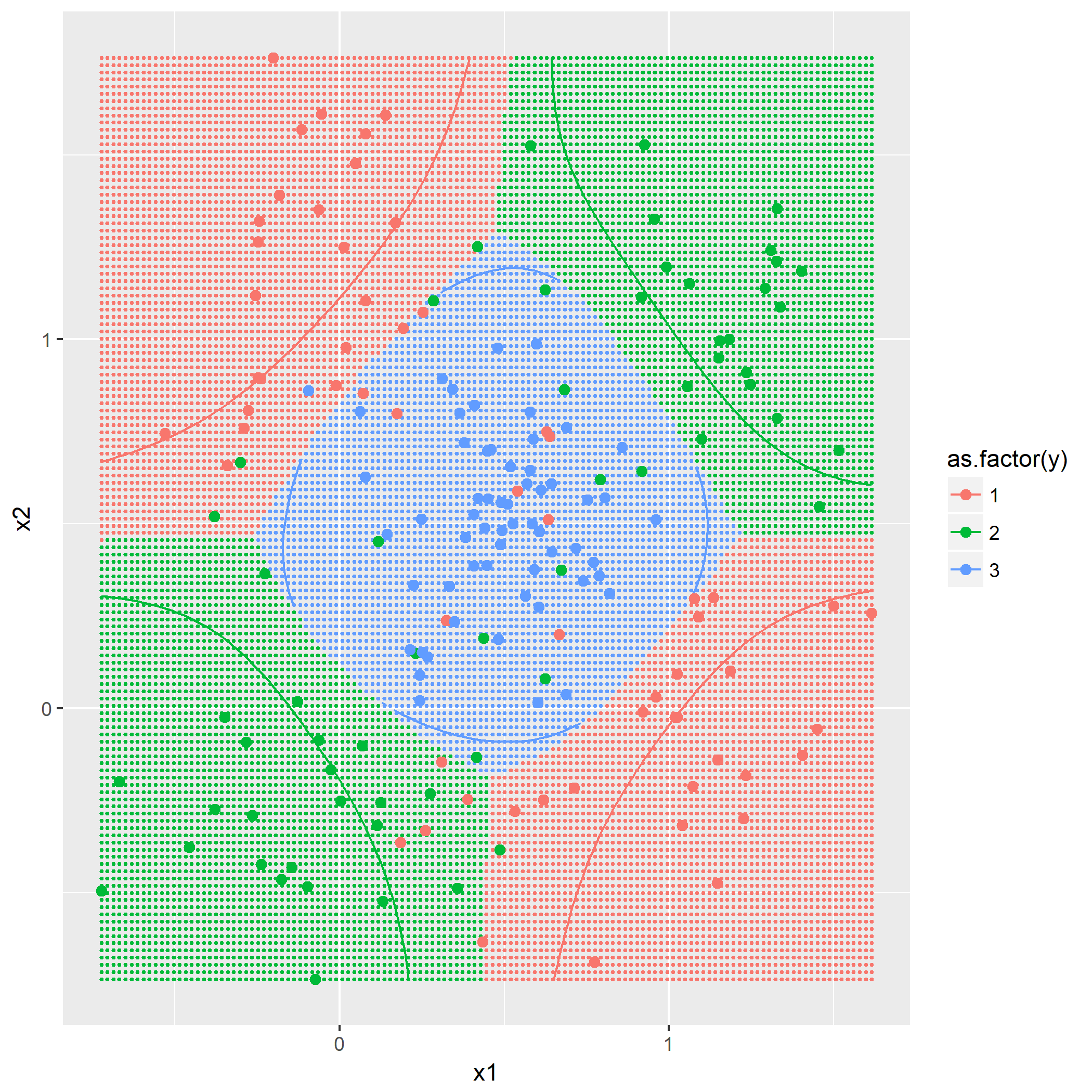
题目7.4 - RBF网络
上一题里面,利用全体训练集对进来的点进行预测,显然是一个自然而然的选择,但是当训练集的样本数很大时,假设进来t个点,那么判定的时间复杂度就攀升到
通过这样的思路,选区代表性的点可以通过K-means方法,然后对于每个将要进行预测的点,计算该点与这些代表点的距离(高斯窗口函数),将所得的“距离”作为线性分类器的输,即利用下述的表达式:
其中:
根据最小二乘法,可知训练后的权重:
第一问就令
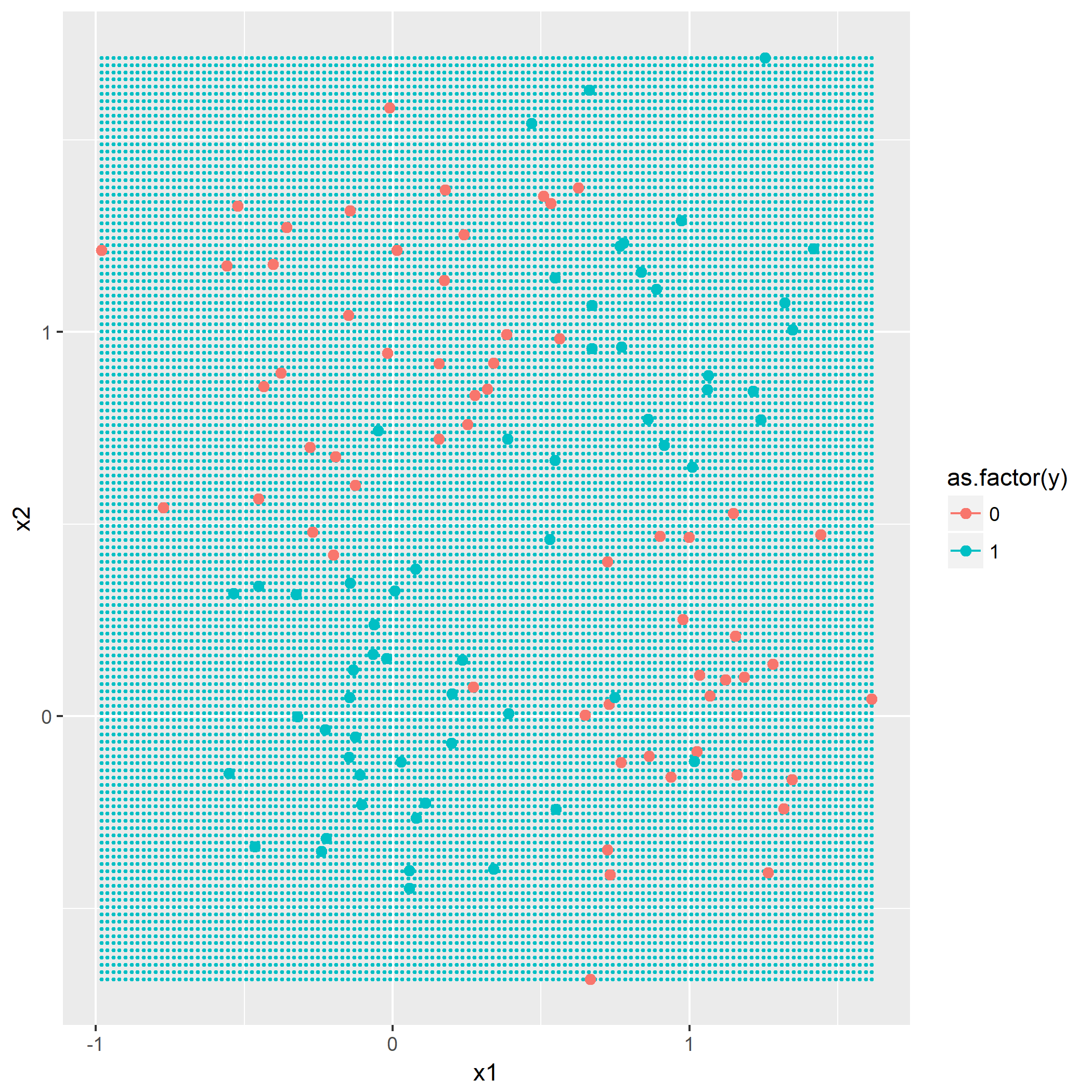
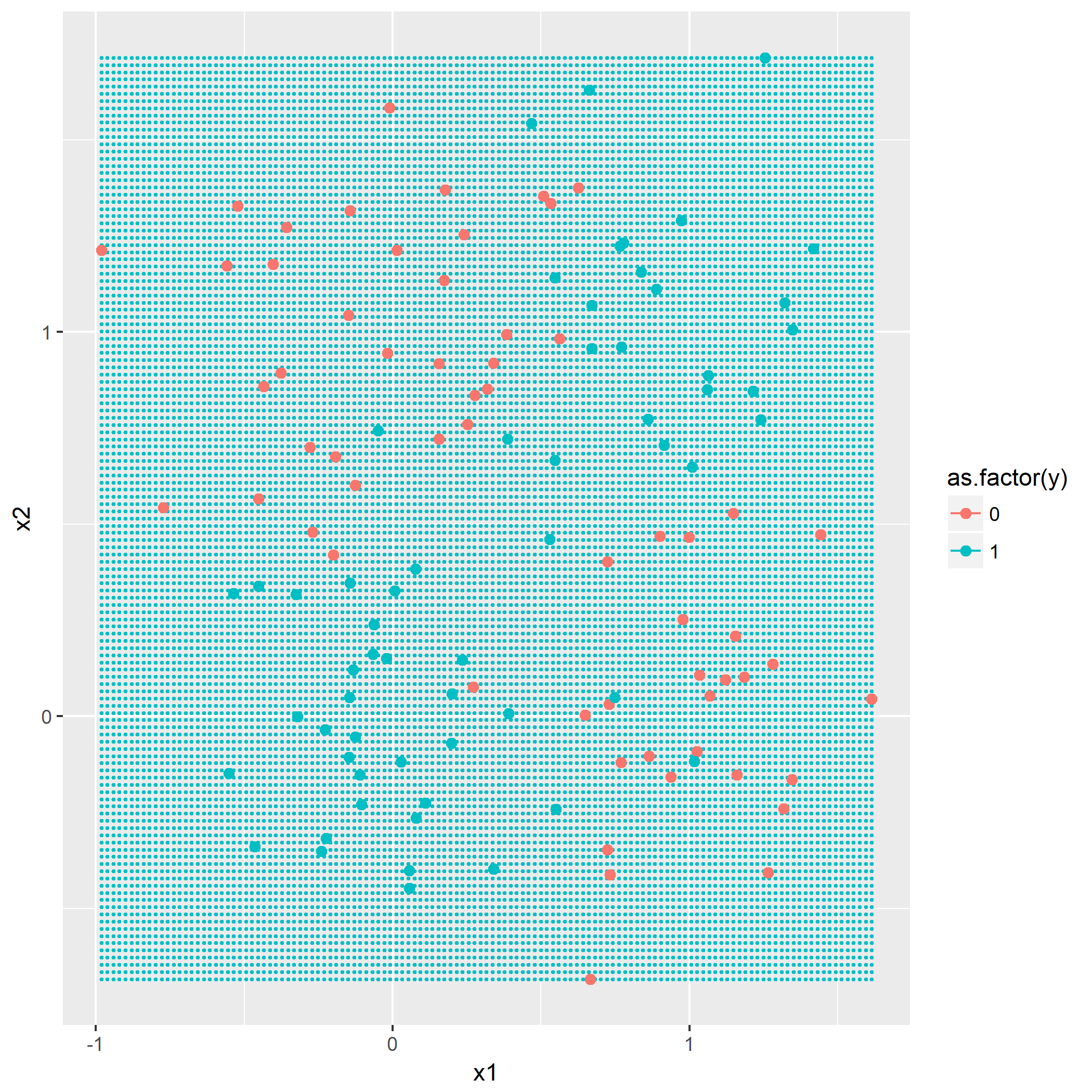
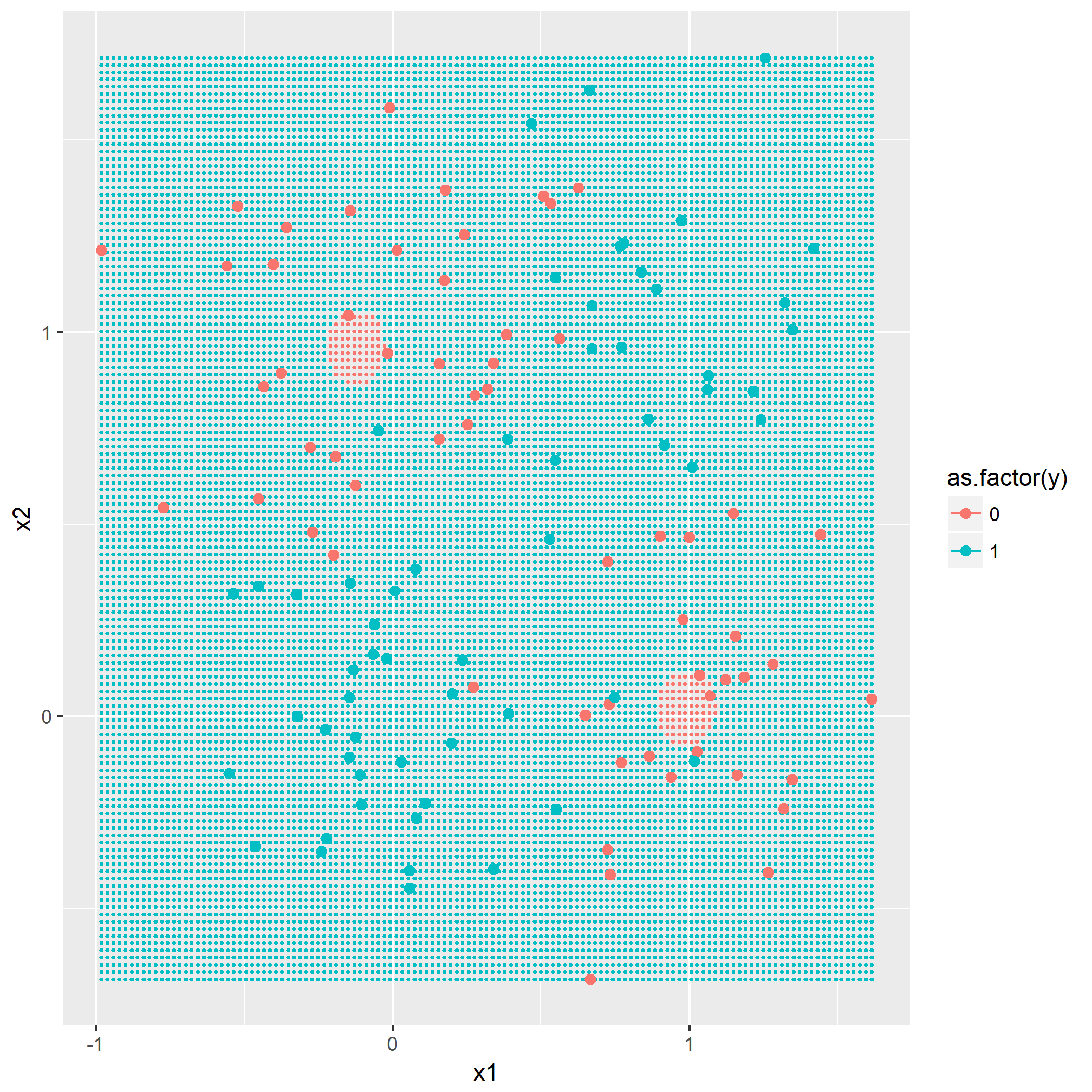
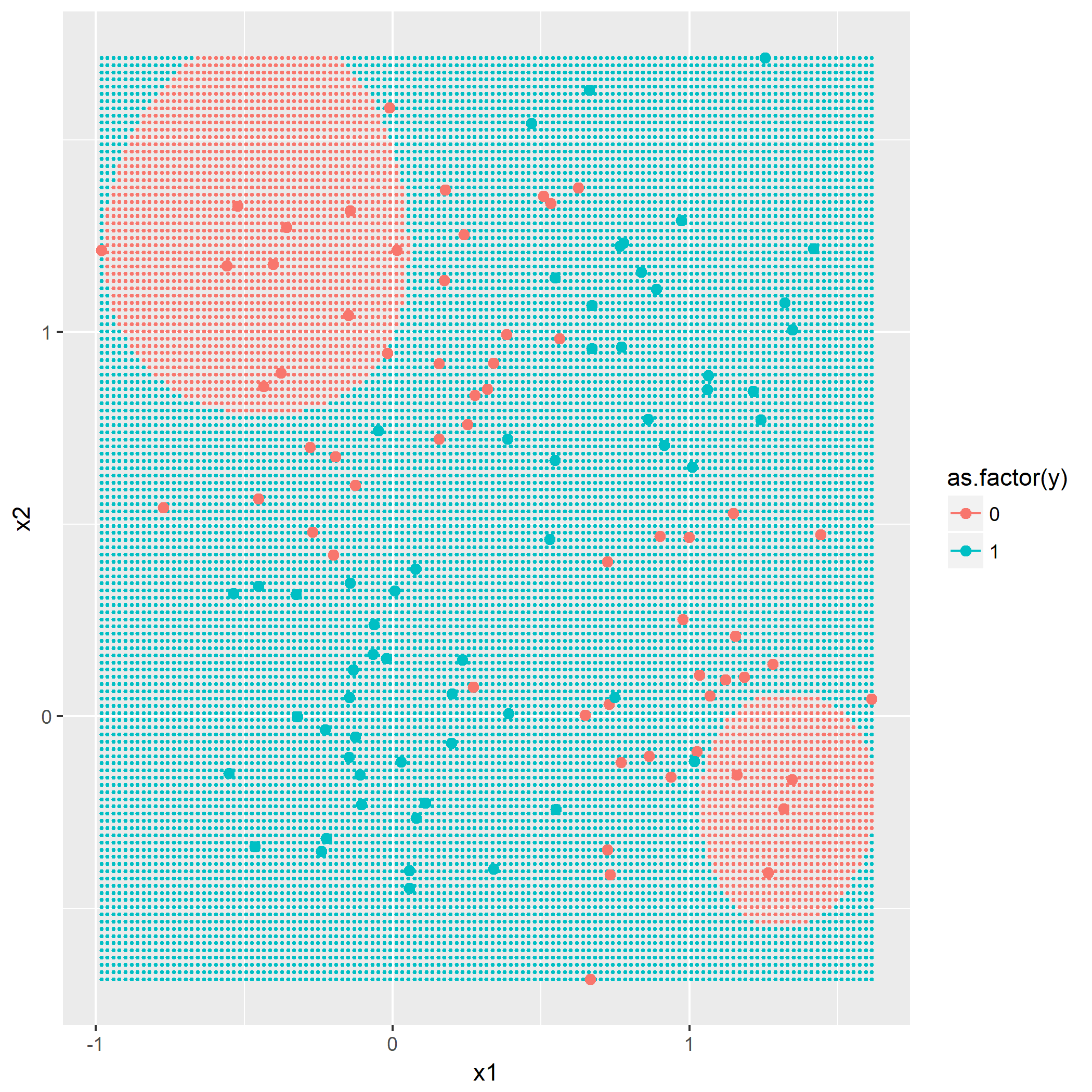
回想一下一个XOR点的分布图,
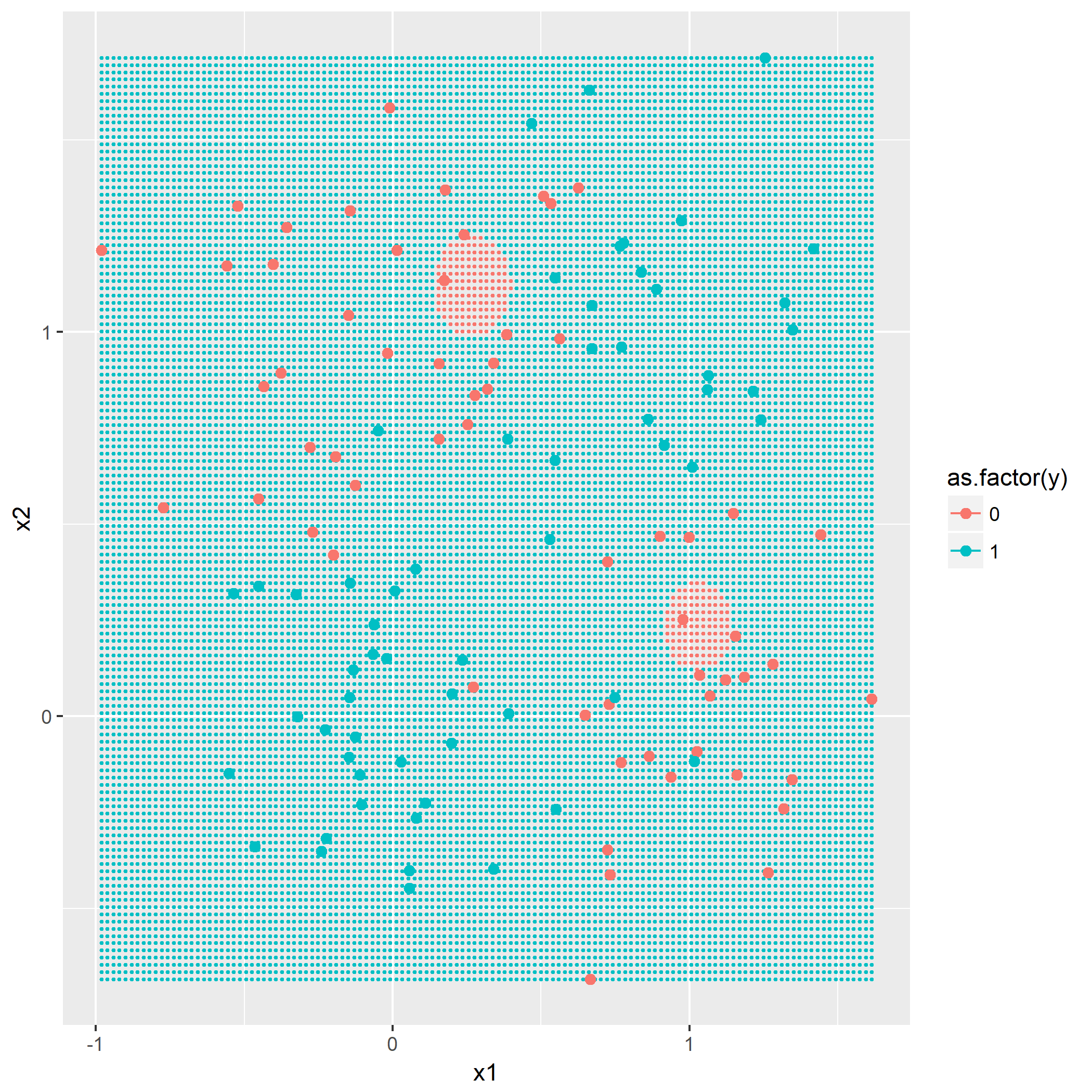
第二问通过修改固定的两个代表点
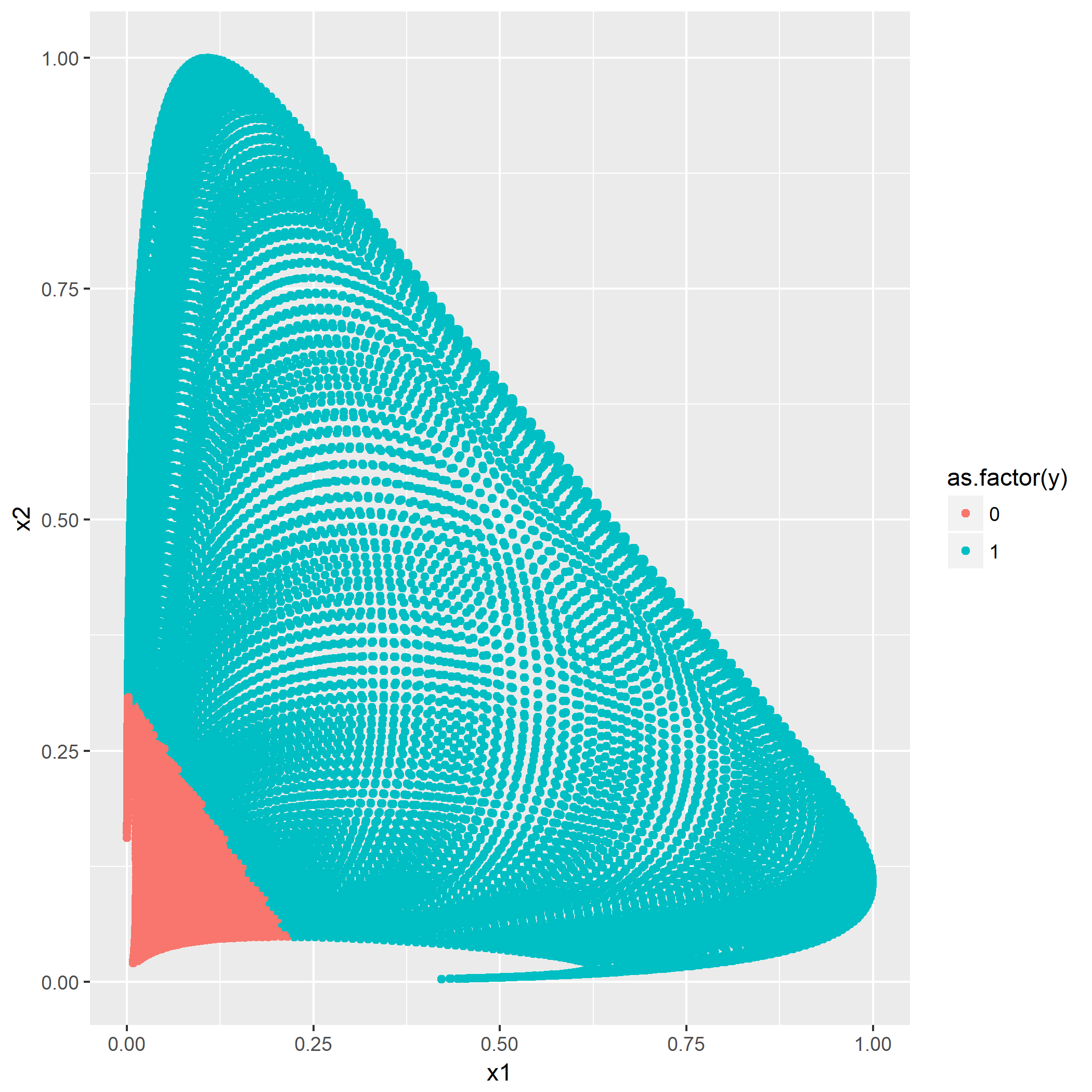
其中横坐标轴为
至此第七章的练习结束。