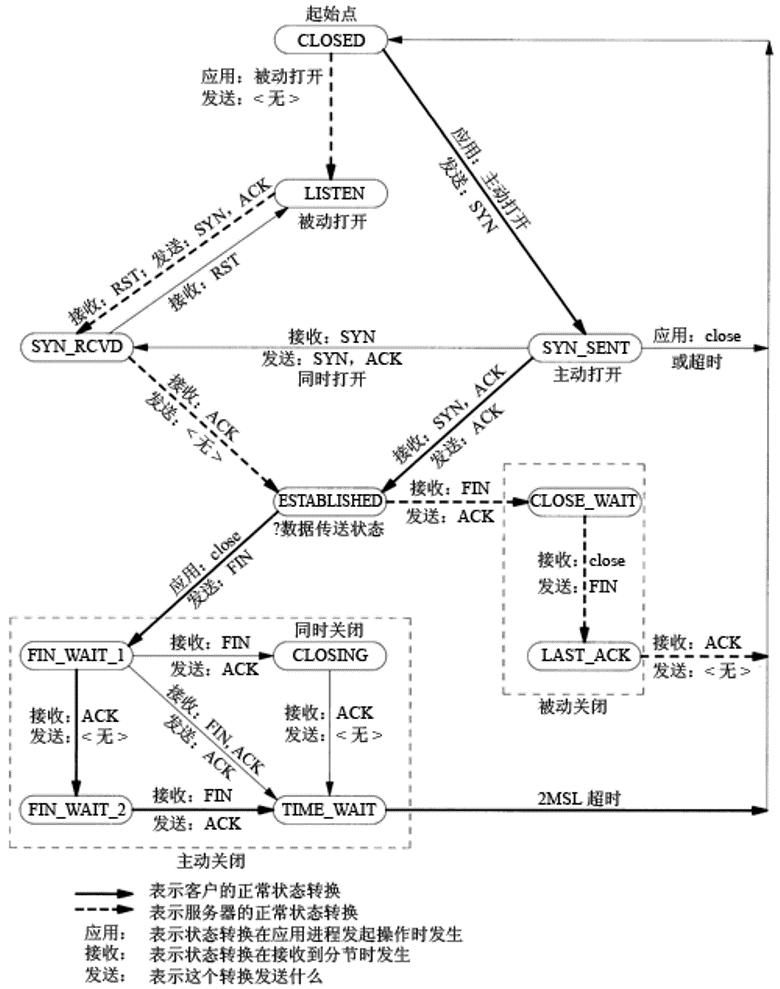
Scott Meyers的Effective C++是C++程序员推荐的读物之一,其中充满了作者的总结出来的编程经验,当年笔者刚入门编程的时候一口气从谭浩强的《C语言编程》开始,《C Primer》、《C++ Primer Plus》等等加起来有10本书学习了如何在C++下编程。当年读这本书的时候也不具备什么具体的编程实践,除了做了书上的一些代码的实验之外,无非也就是在平时的编程中有意地使用书中的编程技巧。时至今日,笔者目前的工作虽然不是以C++来编写实践项目,像一般的Web项目优先考虑的是快捷的Java开发,但是学过的编程技巧却是跨越语言的。并且从这几年的学习编程的经验来看,真正对自己编程能力有真正提升的并不是学习了XX语言。
现在总结起来,笔者的编程能力有了突变式的提升是在大一下学期有一门《数据结构》,学习每种经典的数据结构时,笔者对ADT(Abstract Data Type,抽象数据类型)毫无招架之力,书中对这些经典的数据结构(栈、队列等)有一个抽象的描述,用脑子想似乎很正常,但是在具体实现时常常不知从何下手,除了一遍一遍地抄书上的代码实践之外抄到熟之外别无他法。这样下来,锻炼到遇到一个问题下来,首先是问题的分解,分解到可以直接想到这部分的代码该是什么样子的,把每个最小的部分想好之后向上整合,形成解决整个问题的具体思路。
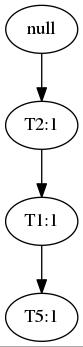
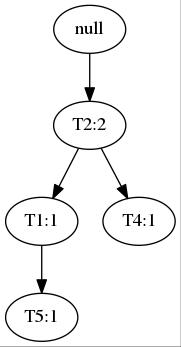
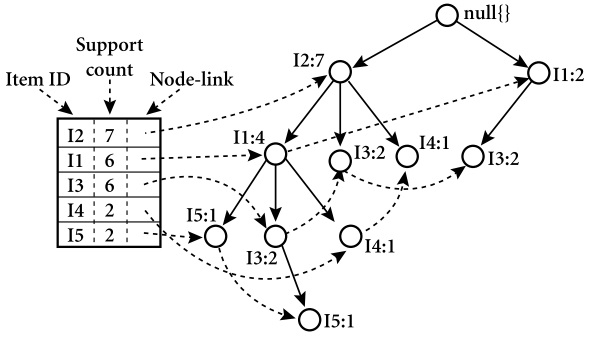
算法 FP-Growth。使用FP树,通过模式增长挖掘频繁模式。 输入: D: 事务数据库。 min_sup: 最小支持度阈值。 输出: 频繁模式的完全集。 方法: 1.按以下步骤构造FP树: (a)扫描事务数据库D一次。收集频繁项集的集合F和它们的支持度计数。对F按支持度计数降序排序,结果为频繁项列表L。 (b)创建FP树的根节点,以"null"标记它。对于D中每个事务Trans,执行: 选择Trans中的频繁项,并按L中的次序排序。设Trans排序后的频繁项列表为[p|P],其中p是第一个元素,而P是剩余元素的列表。调用insert_tree([p|P], T)。该过程执行情况如下。如果T有子女N使得N.item-name=p.item-name,则N的计数增加1;否则,创建一个新结点N,将其计数设置为1,链接到它的父结点T,并且通过结点链结构将其链接到具有相同item-name的结点。如果P非空,则递归地调用insert_tree(P,N)。 2.FP树的挖掘通过调用FP_growth(FP_tree, null)实现。该实现过程如下。 procedure FP_growth(Tree, α) if Tree 包含单个路径 P then for 路径 P 中结点的每个组合(记作β) 产生模式α ∪ β,其支持度计数support_count等于β中结点的最小支持度计数; else for Tree的表头的每个ai { 产生一个模式β = α ∪ ai,其支持度技术support_count=ai.support_count; 构造β的条件模式基,然后构造β的条件FP树Treeβ; if Treeβ!=Empty Set then 调用FP_growth(Treeβ, β); }